类似Center Loss,不过多子类中心
CVPR2018: 更为鲁棒的分类器 卷积原型学习CPL
一、 论文概述
本篇论文提出了导致CNN的鲁棒性的缺乏的原因,是最后的那一层softmax layer,由于softmax loss 是把问题设定在一个closed的空间,就不能很好的应用在open set的情境下。
- softmax loss在0~8的训练集下的特征抽取在二维空间的分布状况。
在0-9的测试集下的特征分布在二维空间下的特征分布状况
由上可以看到softmax层在提取特征,在open-set的情况下,未经训练的类型,难以容易与其他类型混合在一起难以分辨。
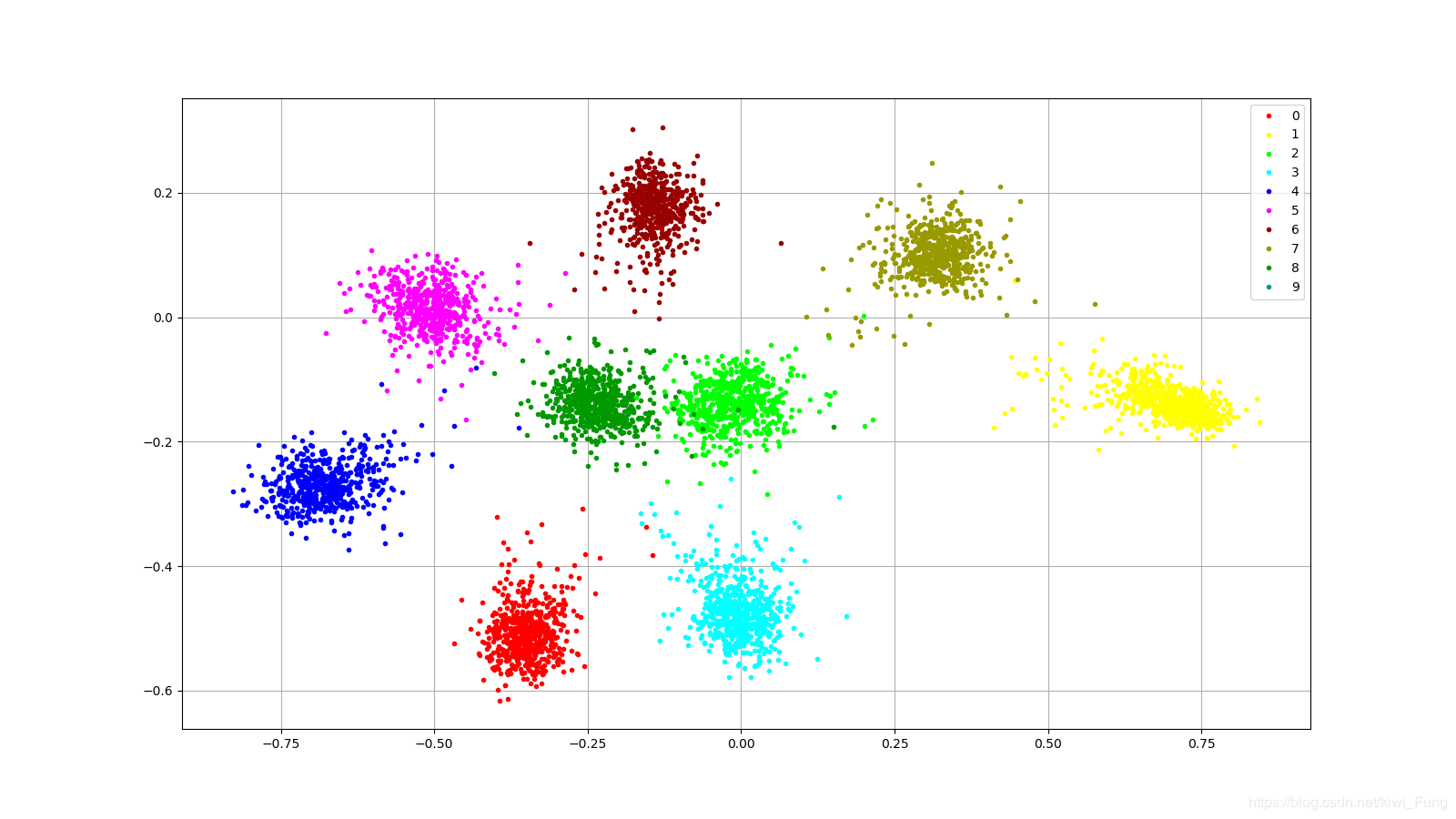
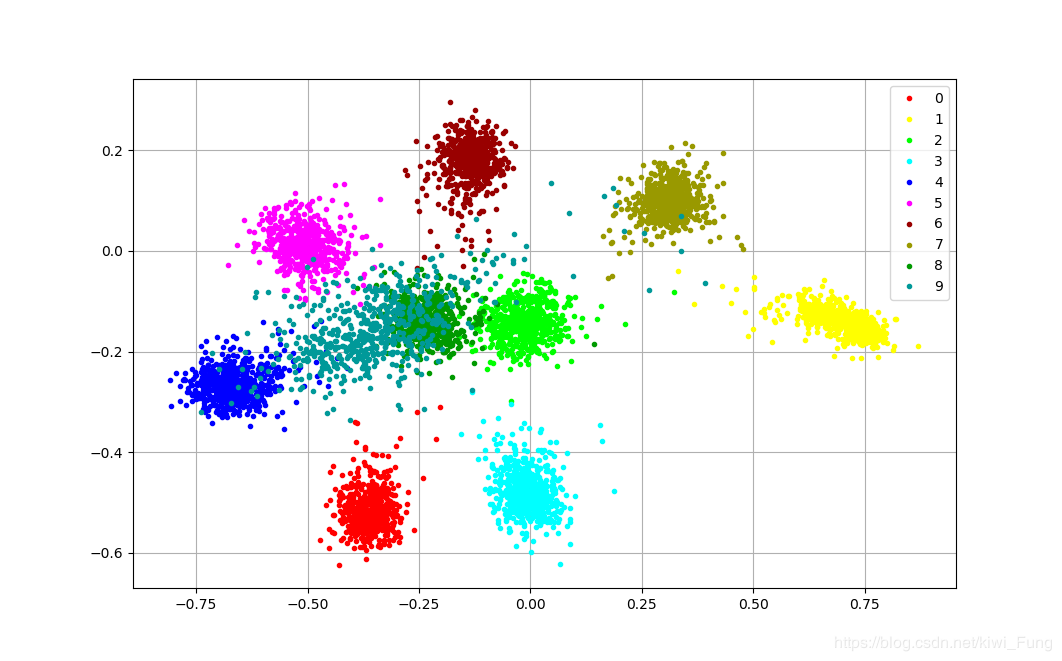
本文由此提出了一个更为鲁棒的方法,去除了最后一层的softmax layer,将CNN和pattern recognition 传统常用的Prototype Learning结合在一起,并提出一些Loss,使得这种组合可训练,并且能够应用于open set的情境下。另外原型学习能够像regularation 那样增强模型特征的类内聚合能力。
由于使用了PL作为分类,在实验的数据集当中能够做到比较好的拒绝与增类学习(就是增加识别的类的数量的能力。)
二、以往相关的工作
对于softmax loss只能做到closed set这一点,也不是第一天为人所诟病。从Facenet开始,人们发现loss function的更改能够做到克服closed set的弊端,越来越多的loss function提出来解决这个问题,在表示学习这方面研究的论文也相当多。
包括有
此处提出的解决方案又是传统算法的端到端训练的改进,传统算法有很多值得借鉴使用的地方,也可以作为深度学习研究的灵感来源。
本论文提出的损失函数直接作用于Prototype 和CNN,没有使用FC会有会就是
三、Prototype Cluster
原型聚类 最常见的方法就是LVQ(Learning Vector Quantization)学习向量量化,属于原型聚类,即试图找到一组原型向量来聚类,每个原型向量代表一个簇,将空间划分为若干个簇,从而对于任意的样本,可以将它划入到它距离最近的簇中,不同的是LVQ假设数据样本带有类别标记,因此可以利用这些类别标记来辅助聚类。 学习向量量化算法如下 ( 摘自于周志华《机器学习》


四、模型架构
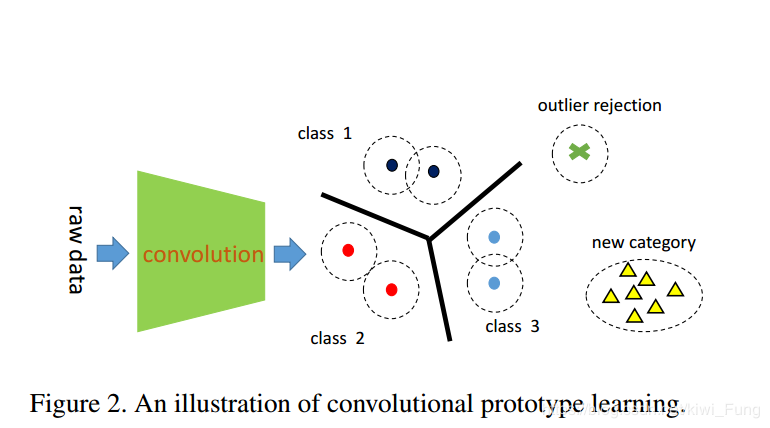 本文提出的模型架构是,数据经过CNN提取特征向量,直接对特征向量进行聚类,每个类下面有k个子类,子类中心初始化随机,记为m_ij ,(i为类号,j为子类号),子类的中心点完全由学习获得。
本文提出的模型架构是,数据经过CNN提取特征向量,直接对特征向量进行聚类,每个类下面有k个子类,子类中心初始化随机,记为m_ij ,(i为类号,j为子类号),子类的中心点完全由学习获得。
经过学习后产生的是所有子类的中心点,测试集的特征向量距离这些子类中心点的距离判断为是从属于哪个类。
那么m_ij应该怎样在学习的过程中更新呢?聚类方法和CNN之间需要建立一个联系,使得梯度可传递。这就需要构建一个Loss Function,来进行指导学习。
4.1 最小分类错误损失
这个网络采用的是最近邻的方法判定是否属于哪一个类
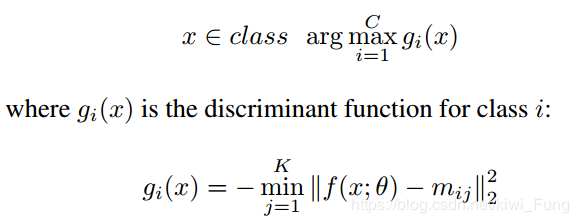 其中一个类中的子类距离输出的向量的最小距离的相反数,就被定义为这个类的区分函数值。
其中一个类中的子类距离输出的向量的最小距离的相反数,就被定义为这个类的区分函数值。
通过以下公式度量分类错误率,其中$g_y$是正确分类
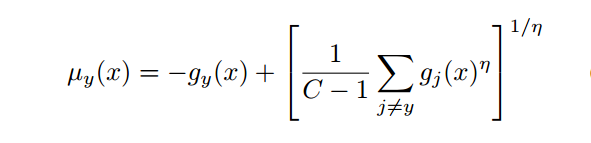 当
当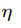 倾向无穷时,就是选择最大的$g_k$,也就是除了正确的类的子类外最近的子类的距离。这个错分类就可以利用两个距离计算距离差,相当于正确分类的最近子类的距离减去错分类最近子类的距离。
倾向无穷时,就是选择最大的$g_k$,也就是除了正确的类的子类外最近的子类的距离。这个错分类就可以利用两个距离计算距离差,相当于正确分类的最近子类的距离减去错分类最近子类的距离。
然后有距离差值,就可以有损失函数:
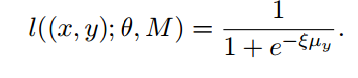 注意到,这里的公式只跟最近的正确分类子类和错误分类子类相关,那么也就对其他子类无关,梯度更新也不会影响到他们。
注意到,这里的公式只跟最近的正确分类子类和错误分类子类相关,那么也就对其他子类无关,梯度更新也不会影响到他们。
4.2 边缘分类损失
我们认为正确分类应该就是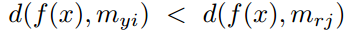 ,错误分类就是
,错误分类就是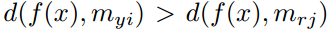 ,正确分类就不需要产生损失,就可以合并这两者为:
,正确分类就不需要产生损失,就可以合并这两者为:
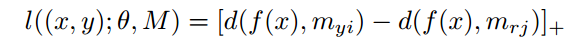 为了能够更好的学习与分类,加上个margin,就有
为了能够更好的学习与分类,加上个margin,就有
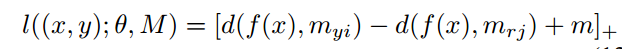 考虑到这个距离在训练过程中,可能大小不一,如果距离差值很小那么就可能无法区分开了。采取相对距离就可以解决这个问题:
考虑到这个距离在训练过程中,可能大小不一,如果距离差值很小那么就可能无法区分开了。采取相对距离就可以解决这个问题:
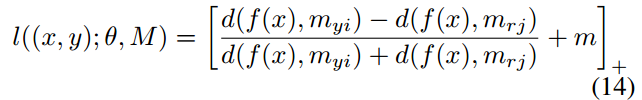
4.3 距离交叉熵损失
利用距离来产生,输入的x属于每个类的概率的大小,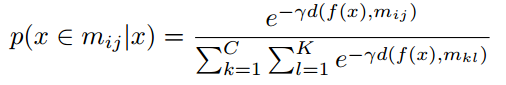 其中
其中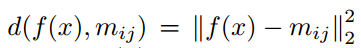 ,这样就可以产生出$P(y|x)$,输入的x属于类y的概率
,这样就可以产生出$P(y|x)$,输入的x属于类y的概率
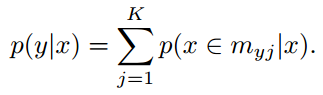 有概率就可以套用交叉熵损失,产生
有概率就可以套用交叉熵损失,产生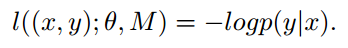 ,同样有概率我们就可以对攻击的类进行识别。
,同样有概率我们就可以对攻击的类进行识别。
4.4 采用原型损失的泛化CPL
直接最小化分类损失可能会导致过拟合,为了避免这种情况,加入了原型损失作为作为正则,提高模型的泛化能力。所谓的原型损失,其实就是以子类中心点为中心的center loss。
采用距离进行判断输入的x从属于那个类,那么其决策边界就是到相邻两个类的子类的中心的距离相等的地方。
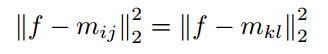 ,也就是
,也就是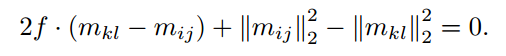 那么在这个基础上,我们加入原型损失来增强模型的泛化能力,做到子类内相聚,而原有的4.3/4.2的损失函数就做到了异类子类间相离,就可以产生一个比较稀疏的特征空间。
那么在这个基础上,我们加入原型损失来增强模型的泛化能力,做到子类内相聚,而原有的4.3/4.2的损失函数就做到了异类子类间相离,就可以产生一个比较稀疏的特征空间。
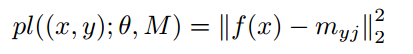
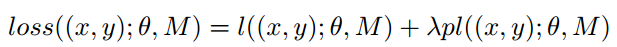
五. 实验结果
- $\lambda$能够指示子类内相聚,越大越聚合。
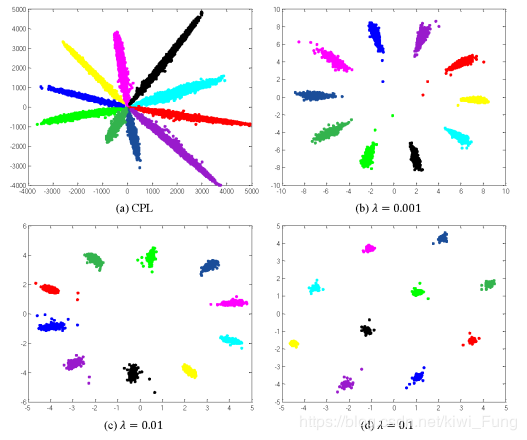
-
准确率相对于soft-max稍有提高,$\lambda$的大小不一定是越大越好,需要寻去一个较为恰当的值,MINIST下的结果
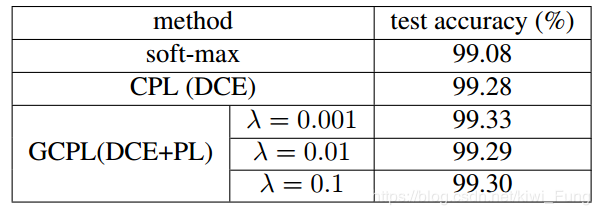
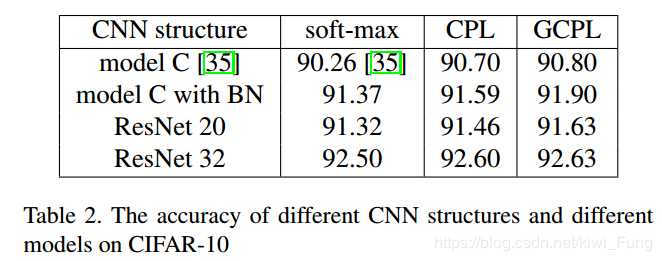
CIFAR10下的结果:
 OLHWDB下的结果:
OLHWDB下的结果: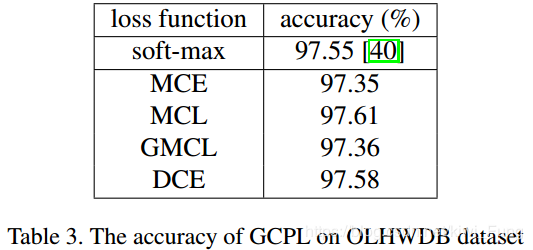
MNIST和CIFAR10都是小数据集,而OLHWDB是个大的手写数据集,各种大小的数据集下表现的效果都不错,所以认为这个模型能够解决分类问题。
-
较强的错误类拒绝能力
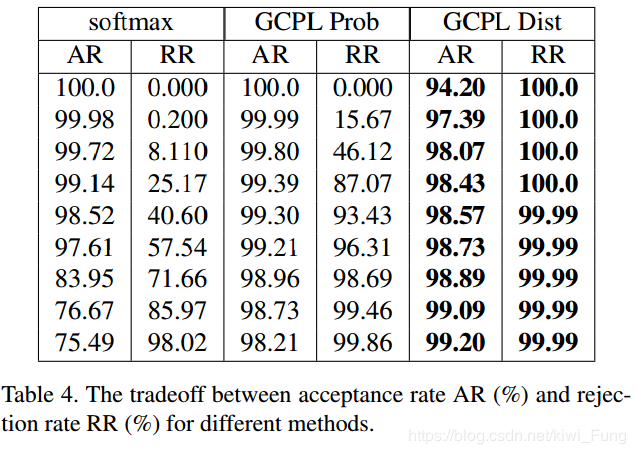 在MNIST中混进CIFAR10的某个类的情况如下:
在MNIST中混进CIFAR10的某个类的情况如下:
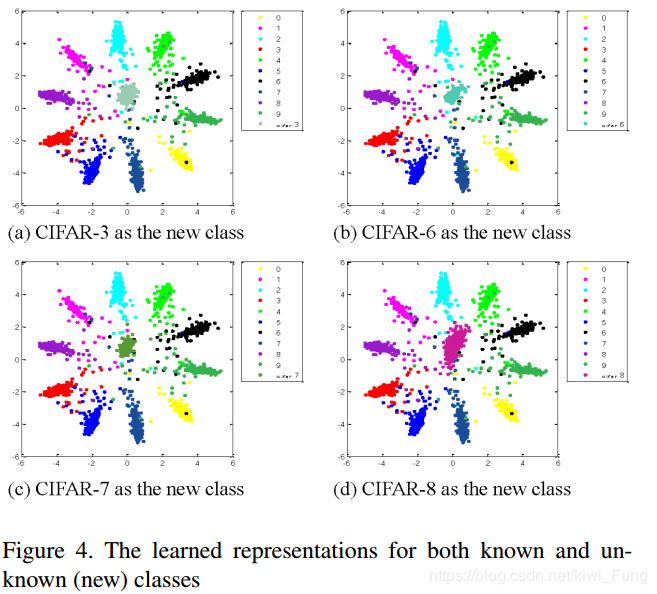 这就和我们上面的softmax的情况有很大的不同,新加入的类和其他类很好的分开,但是这里存在着问题,毕竟输入的CIFAR10和MNIST存在这很明显的差异,这样的攻击好像有点弱,这就能说明其有很好的拒绝攻击能力了吗?其实也未必吧。如果采用上面我的那样的训练9个测试1个的方法可能会更好?
这就和我们上面的softmax的情况有很大的不同,新加入的类和其他类很好的分开,但是这里存在着问题,毕竟输入的CIFAR10和MNIST存在这很明显的差异,这样的攻击好像有点弱,这就能说明其有很好的拒绝攻击能力了吗?其实也未必吧。如果采用上面我的那样的训练9个测试1个的方法可能会更好?
-
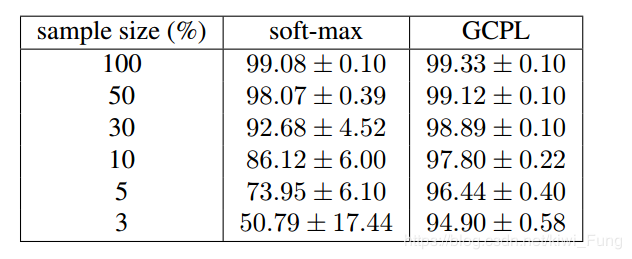
小训练量下也能够有较好的表现效果:
-
每个子类下k的个数的选择
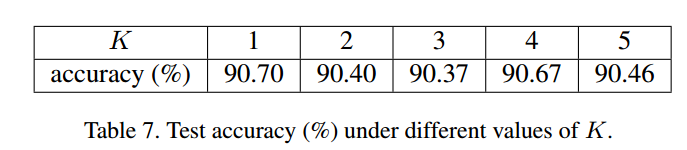 MNIST数据集比较简单,不像多角度人脸那样有很多个差异的从属于同类但是分布有不同的类,采用一个子类就能够达到比较ok的效果,子分类多了,导致被囊括进决策边界的范围大了些,准确率稍下降了点。所以采取了更多的K不一定能够增强模型的能力,但是也不会导致模型能力下降严重,要视数据集情况选取K,当然看样子从大开始选也没什么问题。
MNIST数据集比较简单,不像多角度人脸那样有很多个差异的从属于同类但是分布有不同的类,采用一个子类就能够达到比较ok的效果,子分类多了,导致被囊括进决策边界的范围大了些,准确率稍下降了点。所以采取了更多的K不一定能够增强模型的能力,但是也不会导致模型能力下降严重,要视数据集情况选取K,当然看样子从大开始选也没什么问题。 -
超参数相对soft-max有些增加,$\lambda$ 和K, 相对于表现能力来讲是值得的。