网络自己学会纠偏
ICCV2017: Recursive Spatial Transfromer (ReST) for Alignment-Free Face Recognition (以迭代空间变形实现的免纠正的脸部识别模型)
Background:
传统的脸部识别流程:
- 预定义的平均脸做纠正
- 输入CNN 提取特征用以识别
传统的脸部纠正方法:
- Active Shape Model
- Active Appearance Model (ASM+PCA)
- DNN
脸部识别方法:
- DeepFace (先进行3D纠正)
- FaceNet(不做纠正,用大量数据来弥补姿势差异的问题,所以用了2亿张图片的数据集训练)
- PAM(识别出姿势,然后针对姿势进行识别)
做纠正的好处和问题:
- 在去除角度、动作、表情等与识别无关的东西,增强了识别的鲁棒性,但是同时也弱化了几何性质
- 分两步训练的,但是纠正的目标是将非正脸变形或其他方法得到正脸的图片的纠正,但是这一步的目标在于实现非正脸图片到正脸的映射,与识别存在一定相关性但还是存在着差异,这就可能引起模型落在次最优的可能。
- 单一平均脸难以把握丰富多样的人脸特征。(因为所做的一切是把脸部变形到一个平均脸上,那么所有的形状都一样)
Method
文中提出不做纠正(其实是不把脸部纠正环节独立开来)的识别模型,这个模型把纠正和识别统一在一个模型里面,能够实现纠正适应与识别,达到更好的识别率。(尤其如果要对动物脸部进行识别的话,动物不同品种的脸部结构差异很大,如狗:哈士奇和贵妇狗的差别就很大,不能使用平均脸,虽然人类的脸部结构差异不是很大,但是在动物上这是用不了的。)
受STN的启发提出了ReST的变形方法,多次迭代进行变形,从而实现复杂的变形。
这里为什么空间变形网络需要迭代呢?
一次的变形对于复杂的变形需求可能难以实现最好的纠正,另外通过多次迭代,甚至是分层的方法,可以将复杂的非刚性变换分解为多重的刚性变换,那么就可以实现更为准确的纠正。另外在分层的时候,针对不同的局部另外还有针对的变形,从而更接贴近识别的目标,实现更好的纠正。
ReST的结构
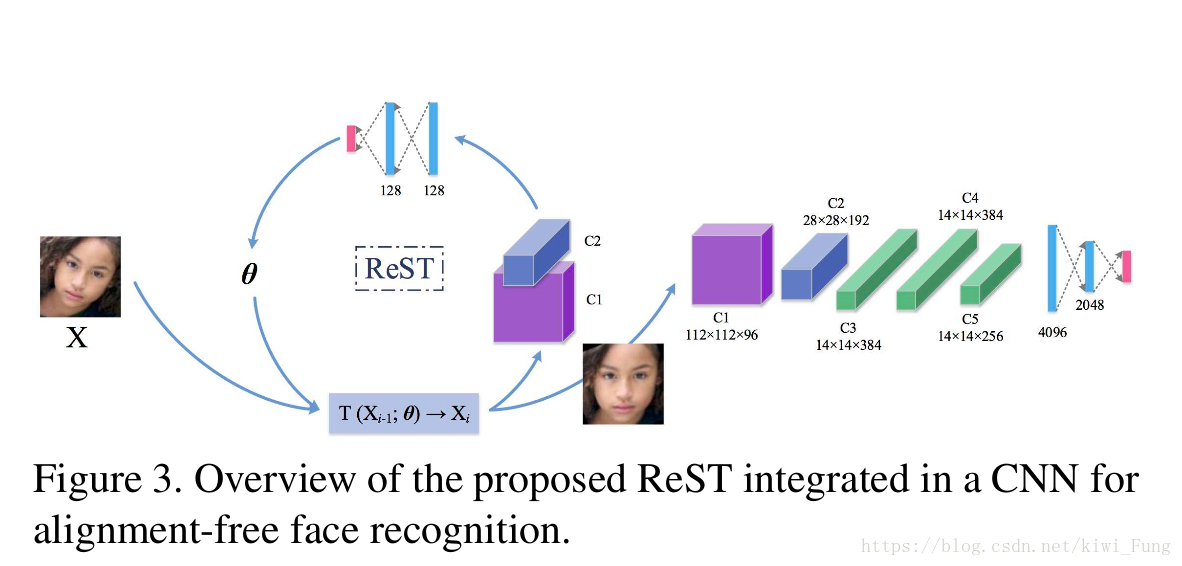
-
X: 输入的图片
$X_i$:第i次迭代后输出的图片
$\theta$:变形函数所需要的参数
C1/C2:两层卷积层,表示的是对图片进行卷积提取特征。
剩下的网络为全连接层,对C1/C2输出的特征进行归约,产生出变形函数所需要的参数。
经过迭代变形后的图片输出进入到识别网络中,卷积提取特征,全连接层归约然后softmax输出训练结果。
注:ReST的C1/C2和识别网络部分的前两层卷积层是share的(目的是为了加速ReST)
由于卷积的大部分计算量在于前两层卷积层,他们的输出更偏向于表达特征能力而不是区分能力。通过将这两层合并能够减少计算量
$C(T(X_i,\theta_i)) \approx T(C(X_i),\theta_i)$

也就是说,当迭代次数到达k+1时,才会去生成新的图片,其余时候都是利用$\theta_i-1$-*当前的归约的参数值,就能得到新的$\theta$,前k次的迭代当中实际上值卷积了一次,实际上的变形是对X的卷积后的变形。
-
输入一张图片,初始时$\theta_0$为单位矩阵,T为变形函数,而$\theta$就是它的参数,从而产生出变形后的图片
-
变形后的图片输入到卷积层当中,抽取出表现能力更好的特征
-
特征输入到全连接层中实现回归得出新的参数$\theta$
$\theta = F(C(X))$
$F()$ 是FC ,用来归约得出$\theta$参数,$C()$就是卷积层C1/C2,卷积后得出特出特征表示矩阵
这里的变形为仿射变换,包括有旋转、缩放、剪切、平移。因而$\theta$包括了六个参数
关于仿射变换的内容,可参考此处
$X_i=T(X_i-1,\theta_i-1)$
$\theta_i = F(C(X_i))$
实际上每一点的输出就是上一轮的输出乘以变形矩阵$\theta$
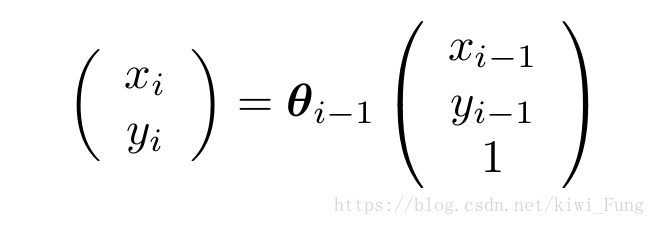
-
1-3 多次迭代后,得出最后输出的图片,输入到识别网络中
- 识别网络抽取特征,经过两层FC和softmax最终得到识别的输出
这里将变形和识别同一在一个网络结构中,就可以实现使两者统一在一个目标下进行优化。这里使用的识别网络为AlexNet,(当然后面为了更好的表现,把网络加深了,可是为什么不采用更深的网络呢?)
层次ReST
虽然循环ReST能够比较好的对于一些刚性形变进行比较好的纠正,但是对于不同的表情,姿势这些非刚性的变形就没有办法有线性的仿射变换来纠正。采用了devide and conquer的方法,对与上一层的输出截取部分继续进行变形。
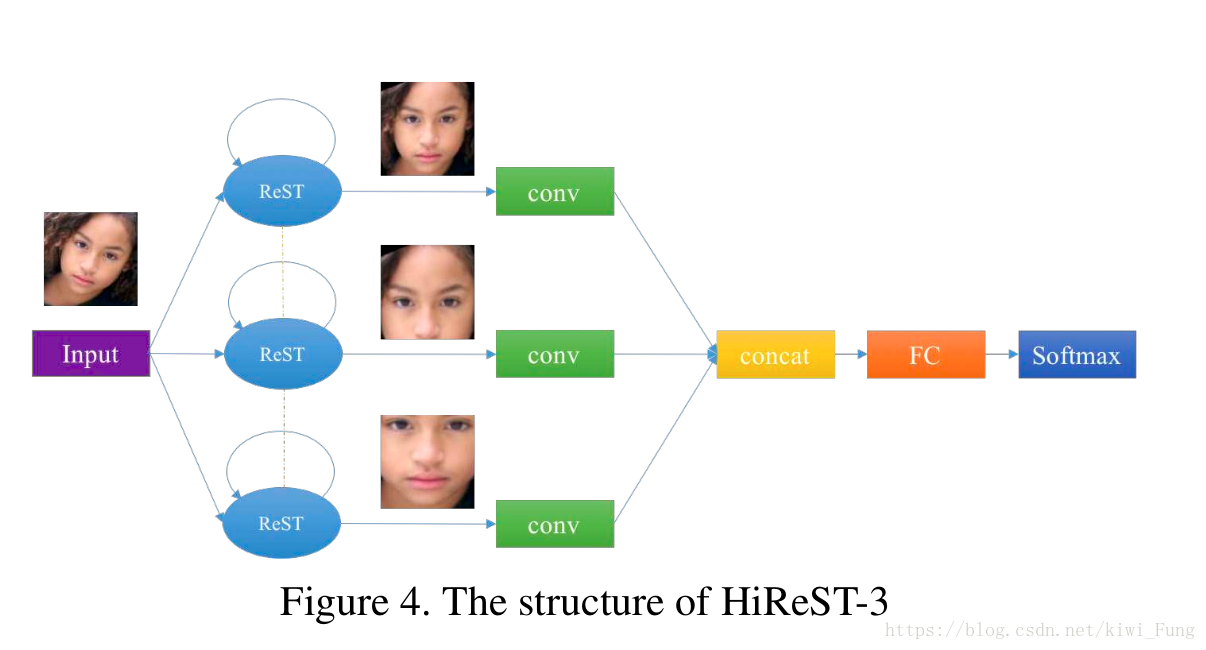
其实完整流程是这样的:
- 脸部检测:输入一种图片,然后利用SURF Cascade来作脸部检测,获得脸部位置,并截取之
- ReST纠正:将截取得到的图片输入到ReST进行纠正
- 特征位置识别:一次纠正后的图片,输入到CFAN 进行检测脸部关键部位(用来切割得到包含不同部位的特征图)
- 第二层纠正与识别:然后将局部特征图继续输入第二层(如果有必要)然后继续纠正,最后将所有的卷积的矩阵concat在一起,FC+Softmax得出识别的结果
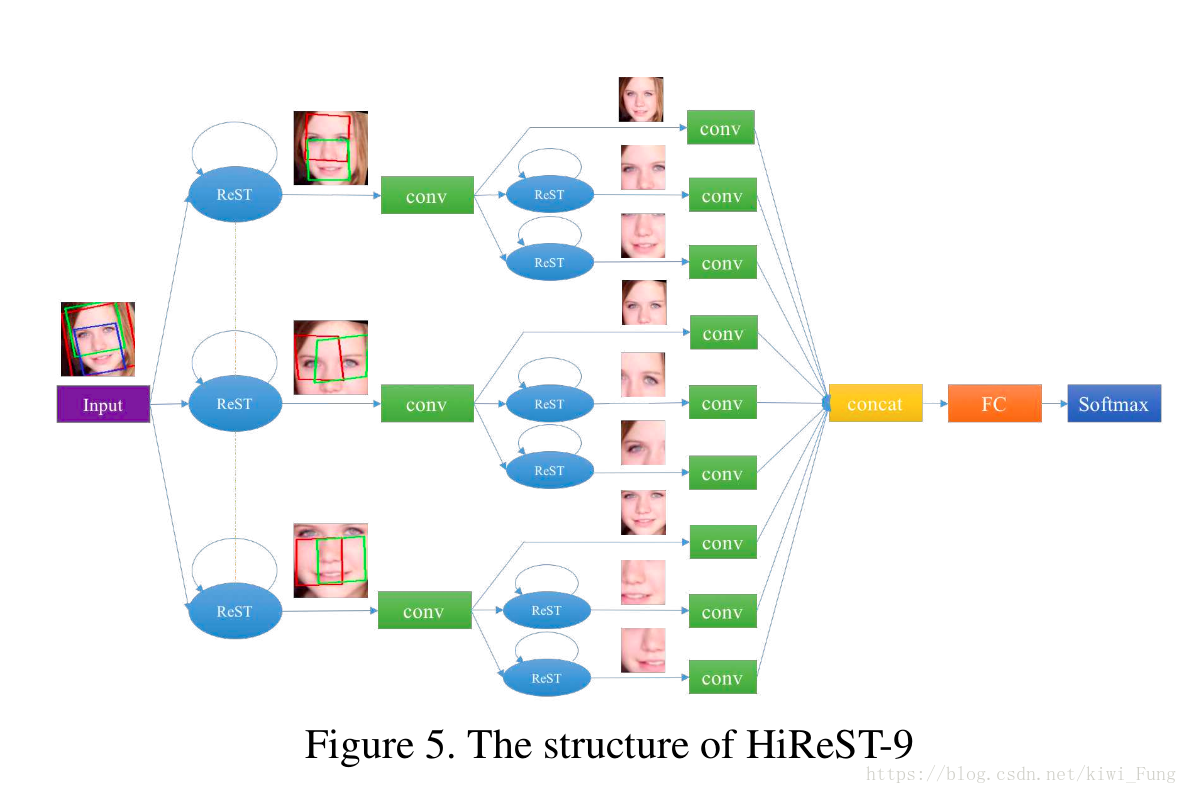
这里有一点比较疑问的地方: 第二层的第二第三个输出是否存在着冗余,因为我们很明显可以看到第四第七个其实与之所识别的位置很相近,去掉是否影响了识别呢?
(文中没有对这点进行描述,或许这个可能在训练的过程当中经过经过变形会有一些差别,但是有必要吗?)
这里的取局部我感觉一定程度上借鉴了DeepID的做法:

DeepID 选取多个局部,期望能够增强局部信息提取的能力。而这里选取的截取局部是希望能够通过分而治之的方式来增强局部的纠正,另外也增强局部的信息获取能力。
另外这个模型可以与现有的方法兼容,进行一定的调整,调整识别部分以及其训练方法,可能能够提高训练效果。
Experiment
多次迭代变形,那么究竟是要多少次迭代比较好呢,这个迭代次数k就是超参,那么需要通过实验确定:
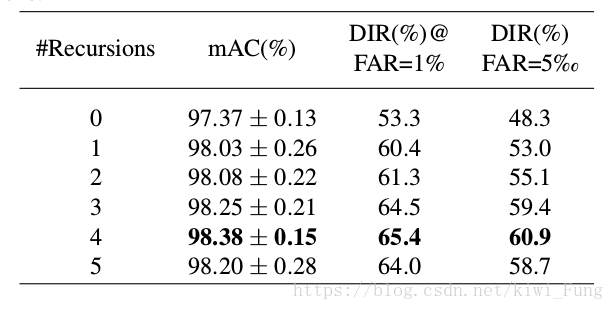
网络结构图对比如下:
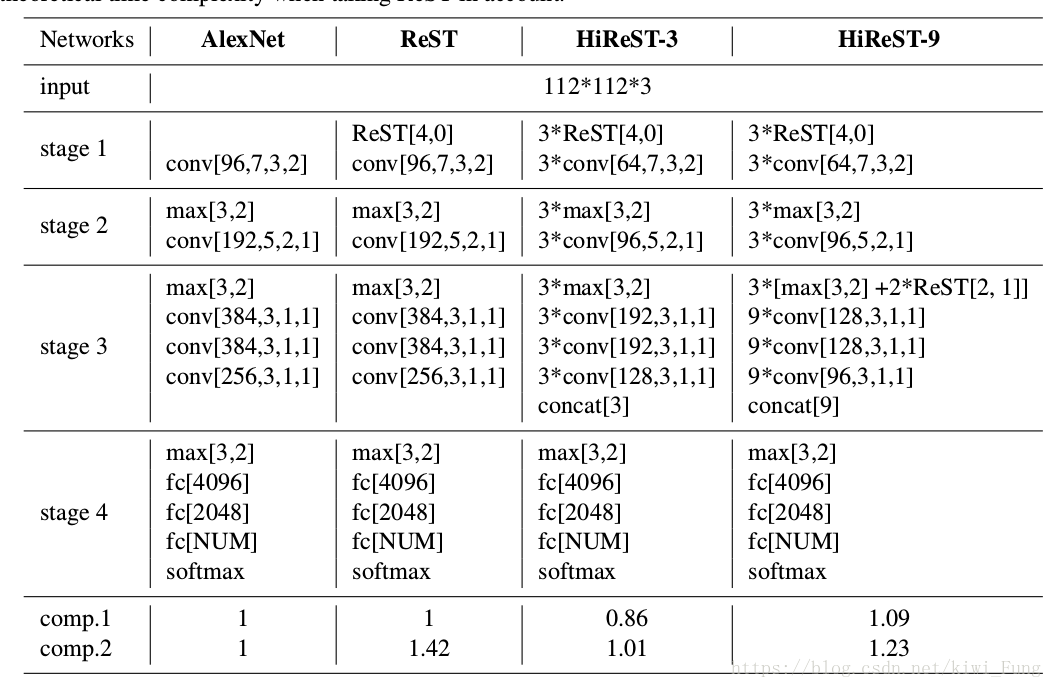

对AlexNet的改动就是将5x5的过滤器换成两个3x3的过滤器,然后在每一个3x3的卷积层之前插入一个1x1的卷积层。这样修改后得出的模型是HiReST-9+
训练结果对比:
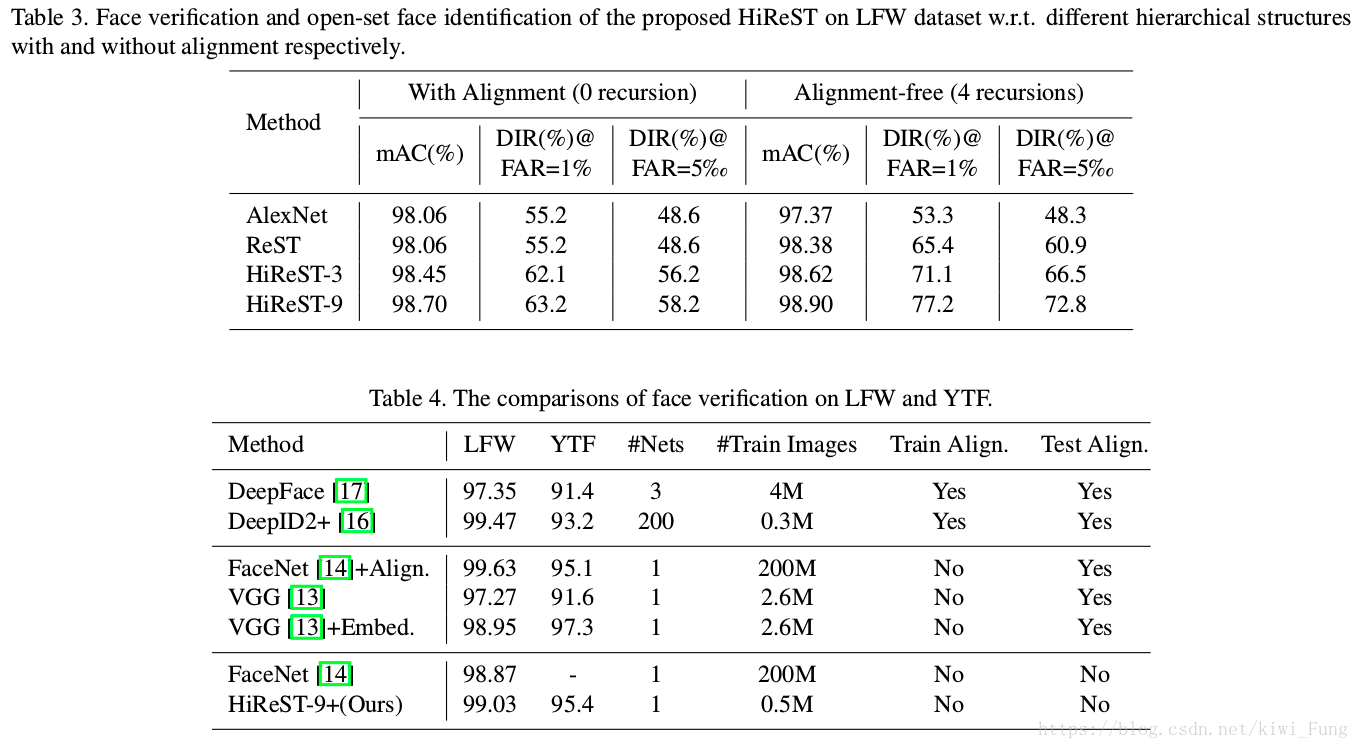
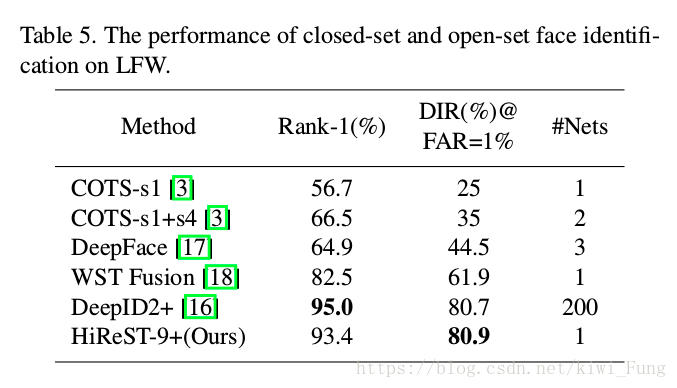
Summary
总而言之,这里提出了将纠正和识别合二为一的模型,利用分层迭代变形实现纠正也是很有趣的做法,另外这个模型具有一定的兼容性和可拓展性,可以考虑更换DCNN,更换训练方式,微调分层等,实现工程上的更为优化的可能性。
另外具有启发的一点是,如果想达到某个目的的最优时,当分多步走需注意是否统一于同一个目标下,否则容易导致次最优的问题。
利用迭代进行逐渐调优、分而治之的算法思想的引入,都在提醒我们,传统算法思想与模型的结合可以擦出不一样的火花。