
1. Overview
视频异常检测很多依赖于像素级的表观和动作特征,这也会使模型对于噪音敏感,且与背景有较大的相关,而背景的冗余信息会增加模型的负担。另外异常检测追求可解释性,检测异常也想知道异常的触发的原因。
在姿态检测已经较为成熟的现在,结合姿态估计,抽取skeleton,对skeleton进行规律学习,那么异常检测部分就能大大降低负担(当然姿态检测端就比较重,但这不是我们关注的重点)。对于skeleton就可以利用常用的Composite-LSTM,这里特别在于使用了两个LSTM,分别做个体和场景下的个体间关系的重构与预测,之间还做了message-passing串联在一起。相对于像素级的模型利用高维度的带有大量冗余信息的模型相对比,基于低维度且信息密集的skeleton能更为高效。
2. Framework
2.1 Skeleton Motion Decomposition
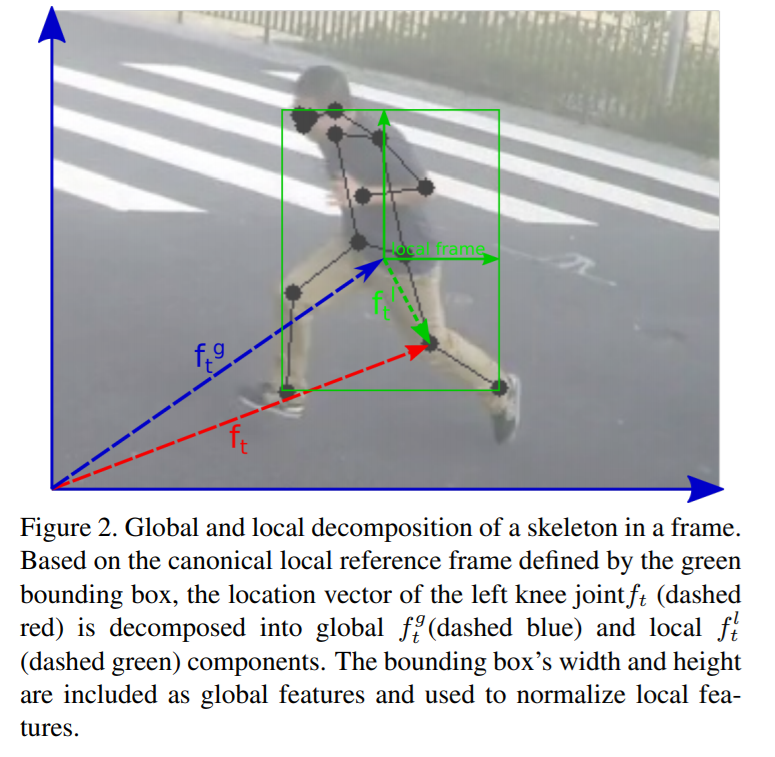
考虑到如果个体与监控摄像头的距离会导致个体的大小差异,远的个体容易直接被无视,这里文中对个体动作的局部与全局解耦,其实也就是将每一个skeleton(x,y) 从基于帧绝对坐标转化为以自身中心的相对坐标(local),那么其自身中心就是global,当然这还需要加上宽和高才能将相对坐标于帧坐标的转换,那么$f^g_t=(centre_X,centre_y,w,h)$ ,而w,h与个体在场景的位置,距离摄像头的远近有关。解耦后,global上可以将个体视作一个点,对场景下多个个体进行建模,而local则可以针对个体运动进行建模。
2.2 MPED-RNN
考虑到即使局部运动,但是其假装运动实际全局静止应当也被视为异常,也就是说,local和global之间的关联也应当在保持,当关联被打破应当视为异常。
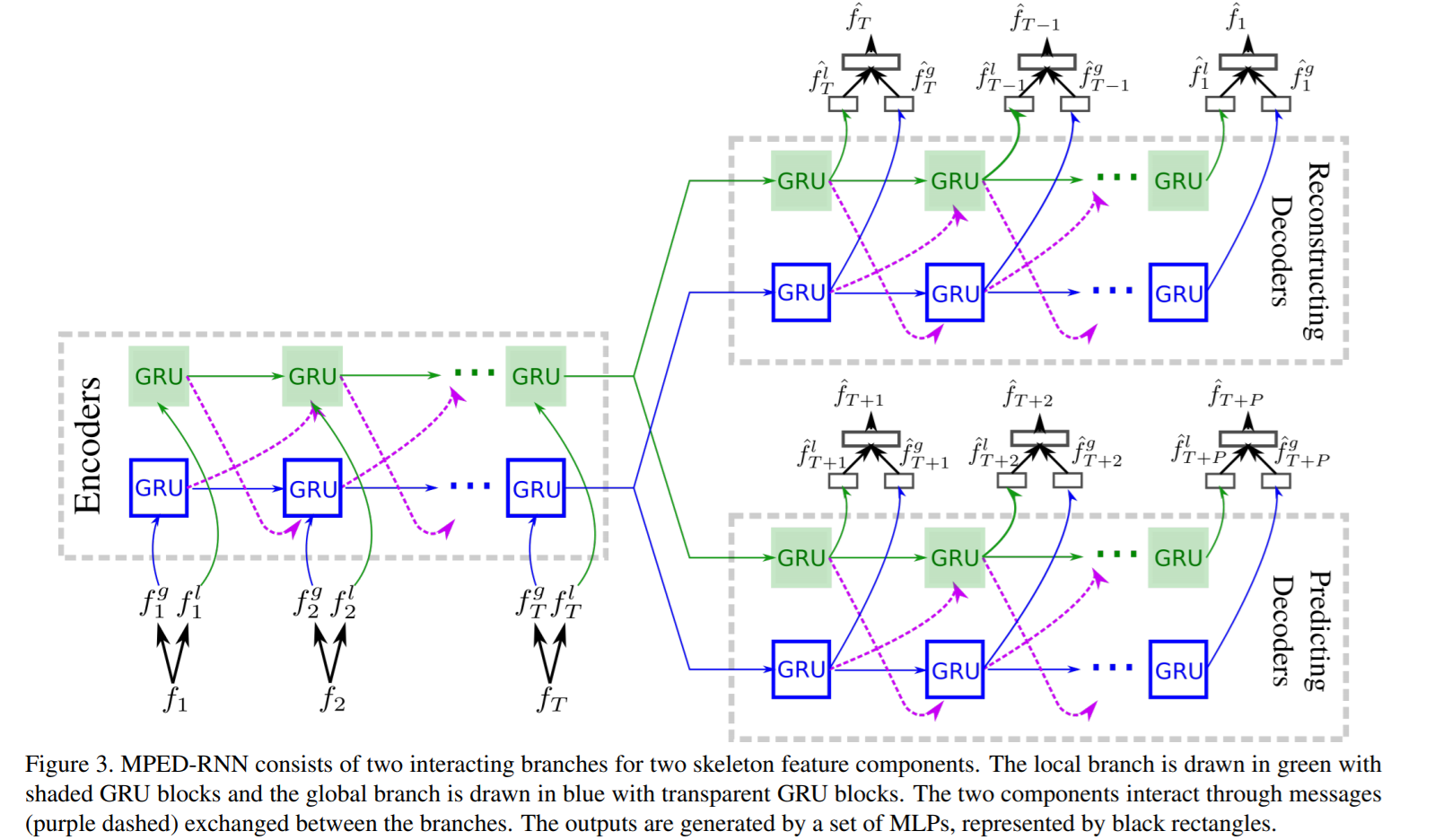
这里将composite-LSTM的LSTM unit替换为GRU(GRU的计算代价更小)。无论是Global或是Local都是由3个GRU组成,而composite-LSTM包括有Encode,Reconstruction, Prediction三个部分,而message passing part其实就是以GRU t-1时刻的隐状态的经过一层FC的输出。
2.2.1 Encoder Part
- 初始化状态为NULL
- t=1,2,…T,
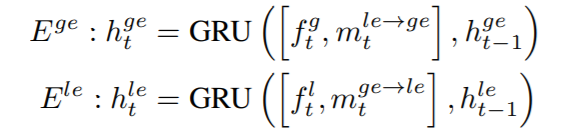
2.2.2 Reconstruction Part
- 初始化为$h_T^{gr}=h_T^{ge} , h_T^{lr}=h_T^{le}$
- t=T,T-1,…1
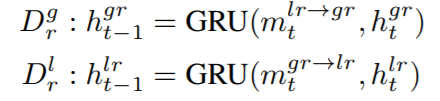
2.2.3 Prediction Part
类似Reconstruction,
- 初始化为$h_T^{gp}=h_T^{ge} , h_T^{lp}=h_T^{le}$
- t=T+1,T+2,…T+P,
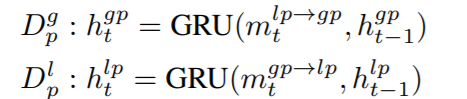
2.3 Training
2.3.1 Sampling
由于个体在场景中的运动包含若干多帧,为了方便训练,使用sliding windows来采样。
2.3.2 Losses
Loss也很简单,只是坐标的重构和预测,那么loss就是基于生成坐标与实际坐标的的MSE,但是考虑到global, local之外更关键的是还原到帧的全局坐标,所以又引入了一个还原后的坐标的MSE。所以loss分为三部分,local\global\perceptual
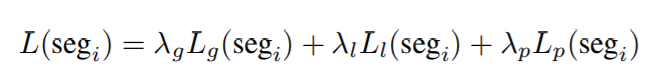
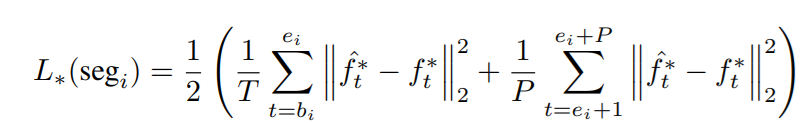
2.3.3 Regularization
由于AEs模型能力过强,容易无法保证模型对正常和异常的还原能力不同,所以引入正则来限制模型的能力。本文在于寻找一个最小的隐向量同时保证模型的能力。通过从训练集划出一部分做验证集,将模型从high capacity训练,记录其lowest validation loss,然后逐步降低capacity来寻找适合的网络。
2.3.4 Detecting
- Extract segments: 从轨迹中采样出包含A个体的segments
- Segments losses: 经过MPED-GRU,计算每一个segments的三个loss
- Skeleton anomaly scores:对于包含有$f_t$,求多个segments下$f_t$的平均异常分值,
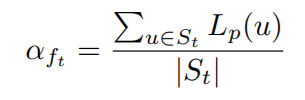
- frame-level anomaly scores:一个帧下可能有多个个体,那么该个体该时刻最大的异常分值即为此帧的异常分值。
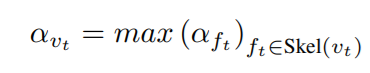
2.4 Datasets
- 采用Alpha Pose 来提取skeletons
- 利用光流和skeletons来对相邻帧的skeletons进行配对。
- 提出测试集中异常与人无关的事件,产生HR-ShanghaiTech, HR-Avenue
3. Experiments
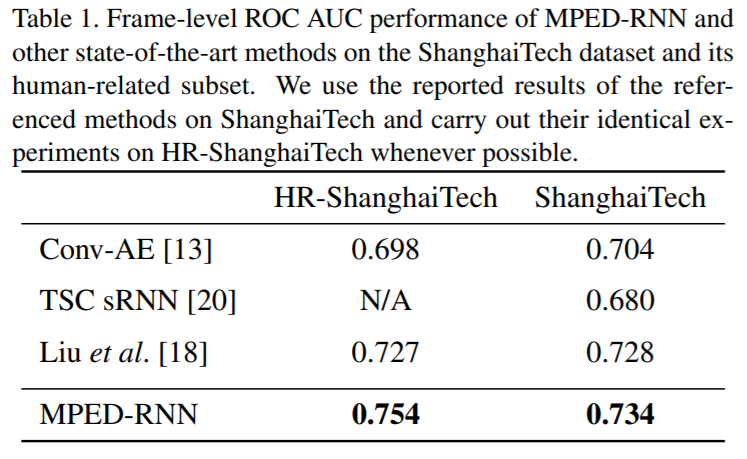
只是比较AUC的话,HR-ShanghaiTech的75.42%,HR-Avenue的86.31%是看起来不错,但是对比起Precision Recall-AUC就有点惨不忍睹了:
HR-ShanghaiTech 66.17%, HR-Avenue:66.25% (by evaluatint pretrained model released on github)
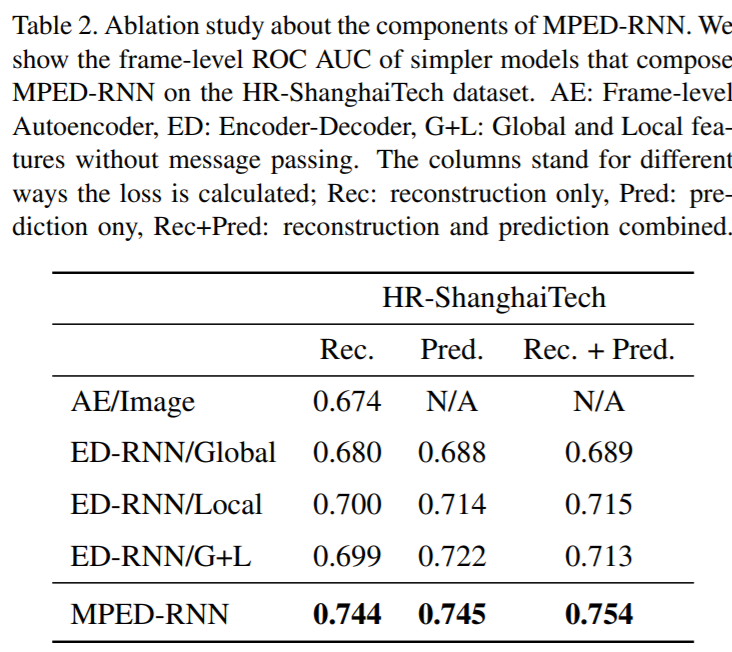
这里主要在于对比出message passing的作用。
predict 和 ground truth 还是会有一定差异,但是其差异相对来说较大动作的异常小。
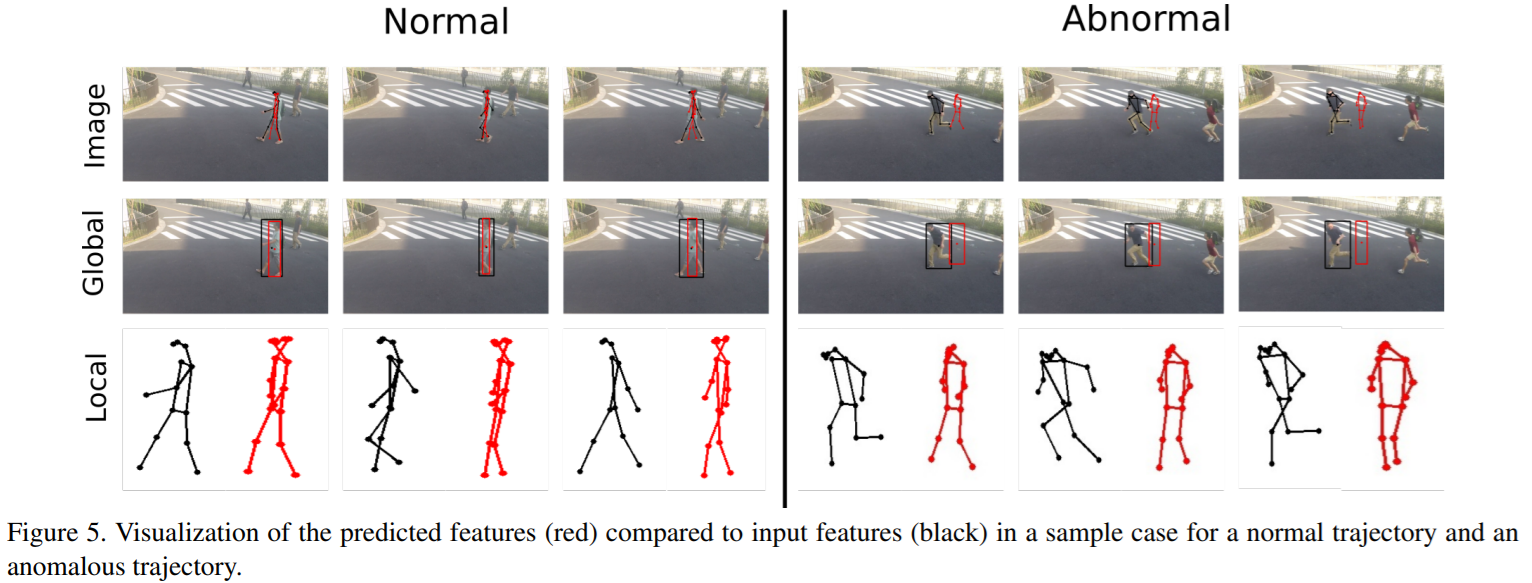
无论是基于object 还是基于skeleton,detection 都会影响实际的结果,玻璃/镜子带来的错误检测,或者检测失准都会影响模型的能力。

4. Discussions
- 这篇文章将异常检测引入human-related的概念,提出skeleton based的异常检测方法,为可解释指出了一个方向
- 同时文章对ShanghaiTech、Avenue清洗出human-related part,也把skeleton和trajectory都已经生成好,可以供后续使用。
- 模型的AUC或许美丽,但是PR-AUC却是较低,这说明模型实际仍然存在问题,有改进的空间。另外Composite-LSTM的是否能被替代?基于GNN?
- Local 和 Global的解耦能否被引入到其他方法中?
一家之言,难免疏漏,望不吝斧正~
本文同步于个人专栏CV上手之路