ICCV 2017 : 通过学习深度属性知识以异常检测与解释

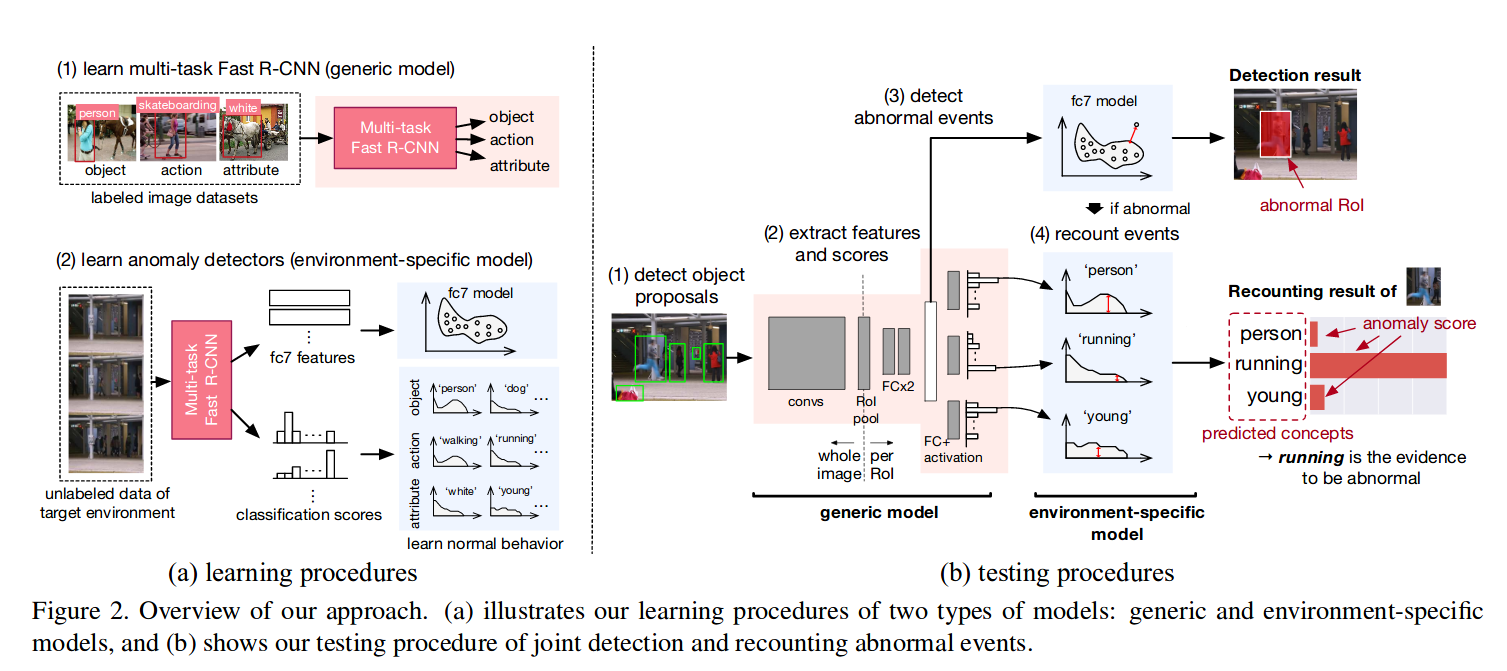
1. Overview
现有的异常检测方法都是在做检测,但是异常的判定原因也是应当关注的点,这有助于人去理解与决策。本文把Multimedia Event Recounting(MER)与异常检测联系起来,通过物体检测与属性知识结合一起,能够同时做到对异常事件的检测和解释。
异常是罕见事件,且与正常事件相异,而异常事件是依赖于环境的。常见的异常检测方法是:
- 通过训练样本来学习环境依赖下的正常模型
- 利用这个模型来检测异常
文中认为使用类似AEs的模型来学习视觉信息是不足够的,学习使用基础的视觉信息(object\action\attribute)能够有助于进行异常事件解释的。那么文中提出的首先通过Fast RCNN进行多任务学习,学习以上三个视觉概念信息,然后通过异常检测器在特征和分类分数上来学习环境特定知识。
具体可以分为以下四个流程:
- 物体位置proposal
- 提取特征,利用multi task Fast RCNN来产生每一个object proposal中的特征
- 异常分值,特征输入异常检测器产生异常分值
- 解释异常事件,通过特征输入多个基础视觉概念信息的分类器,用以对异常事件进行解释
2. Model Design
2.1 Fast RCNN for Learning Generic Knowledge
2.1.1 Articheture
选择Fast RCNN而不是Faster RCNN是论文提出时还没有后者(同样是ICCV 17的论文)。
backbone是AlexNet,三个任务(object/action/attribute recognition),以proposal和图像作为输入,去掉原有的分类层,AlexNet后的ROI Pooling对于每一个ROI依次进行特征提取,经过两层FC,特征特征,然后分别接三个FC with sigmoid作为三个任务的分类器。
没有使用boundary box regression,毕竟这依赖于异常的物体的类别,而这在目标数据集中并不知道,以此一定程度上避免了模型对于未知类的发现能力较低的可能。(这一点比CVPR 2019 的object centric的论文更加合理)
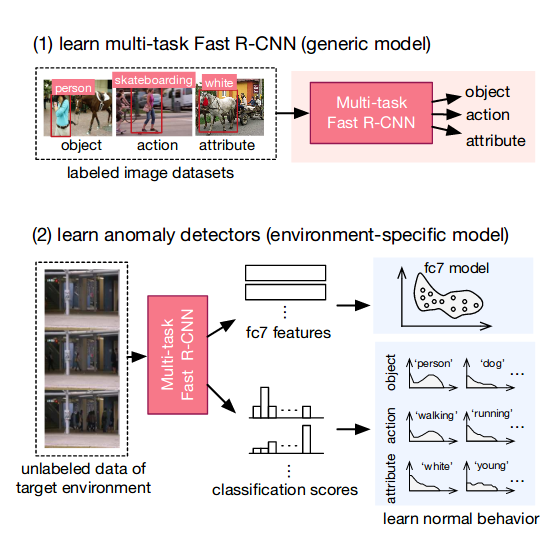
2.1.2 Dataset Selection
以COCO数据集学习object,以Visual Genome数据集学习attribute和action,两个数据集的交集已经被剔除,然后筛出了Visual Genome数据集最常见的45个attribute和25个action。这些数据集都是静态图片,没有使用视频是认为静态背景的视频的motion都是没有被标记的,无法直接使用。
2.1.3 Learning Details
基本与Fast RCNN一致,主要在于剔除boundary box regression,随机选择一个任务然后进行学习,更新包括share layers 和对应的classification layer。
2.2 Abnormal Event Recounting
在获得三个basic visual concept之后,还不够,我们还是不知道到底异常是由于哪一个concept导致的,所以这就需要做一个预测以解释到底是哪一个concept导致异常。也就是模型需要同时完成三个分类任务,然后对于每一个分类任务还需要产生一个异常分数。先通过监督学习分类任务,在输入异常检测的样本,以高斯核进行核密度估计得到一个连续的核密度估计函数,那么测试时,预测类的密度的倒数就是该concept的异常分值。
2.3 Anomaly Detectors
文中使用了三个异常检测器:
- 最近邻方法:利用NN计算与测试样本特征最近邻的训练样本的距离,以距离为异常分值的度量。
- one class SVM:异常分值就是测试样本距离以RBF核的OC-SVM的决策边界
- 核密度估计,对特征KDE计算核密度函数,该特征的密度倒数为异常分值
训练时,减少计算,将帧以3*4的方格划分,所以总共有12个检测器。对于每一个object proposal位置的中心属于哪个方格,那么这个proposal就归属于哪个方格。对于FRCN的output FC7特征进行乘积量化压缩为128维以给NN进行聚类,而对于OCGAN和KDE的特征变量则是通过PCA缩减维度到16维。
3. Experiments
实验是在Avenue17(剔除了{01,02,08,09},认为这些包含着静态异常被错误标记了)和UCSD上做的。比较了HOG\SDAE等的特征提取与自身的三个任务的消融实验。
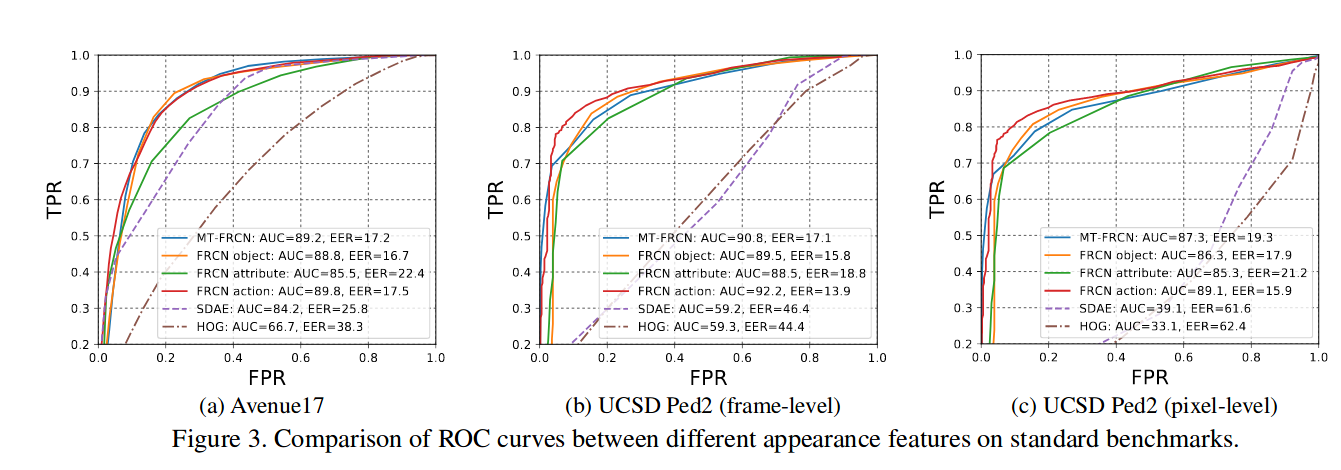
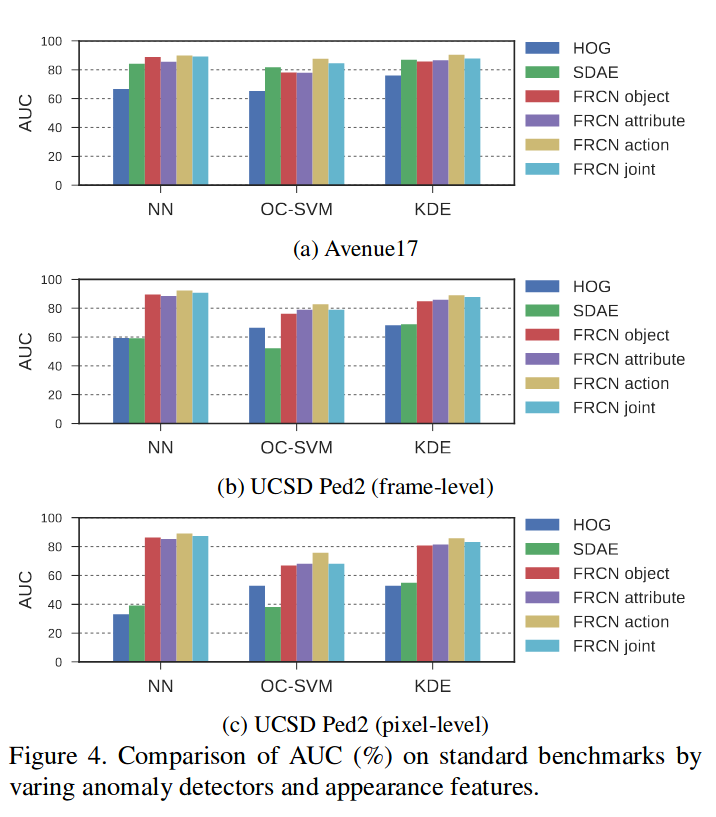
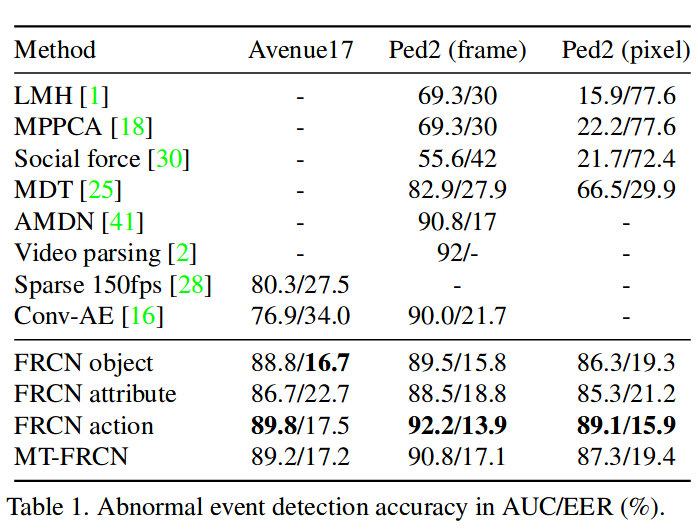
对比结果比较有趣的是仅仅就action一个任务就能够达到较好的结果,也就是通过学习广泛的动作分类进行预训练,以此提取做异常检测的特征提取可能是一个可行的解决方案。而NN相对于其他的结果来说更好,但这种要求测试时所有的样本特征都是可以访问的做法是否practical?而KDE通过训练结束后,通过所有训练集的特征计算一个全局的正常特征的核密度估计函数,以此来计算异常分值,高效而且更为可行。以统计整个训练集的特征进行异常检测相对于非统计方法更加可解释而且效果会相对更佳。但是对于接近正常的异常与罕见的正常这些较难的问题可能存在的无法检测与无法解释,当然这些hard sample的准确检测是相当困难的。
模型在Ped1上的表现很差,作者解释是因为分辨率太低导致模型太差。同时模型并没有使用到光流等运动特征,纯粹通过一帧的appearance进行异常检测。

4. Anomaly Recounting
现有的benchmark对本文的设定有三个不足:
- 数据集太小而且异常的变化很少
- 异常的定义是由用途决定的
- 由于真实的异常时间的类标缺失,很难验证解释效果
通过将三个分类的数据集按照类别切分为seen类做训练集,unseen类做测试集来比较异常解释的能力。
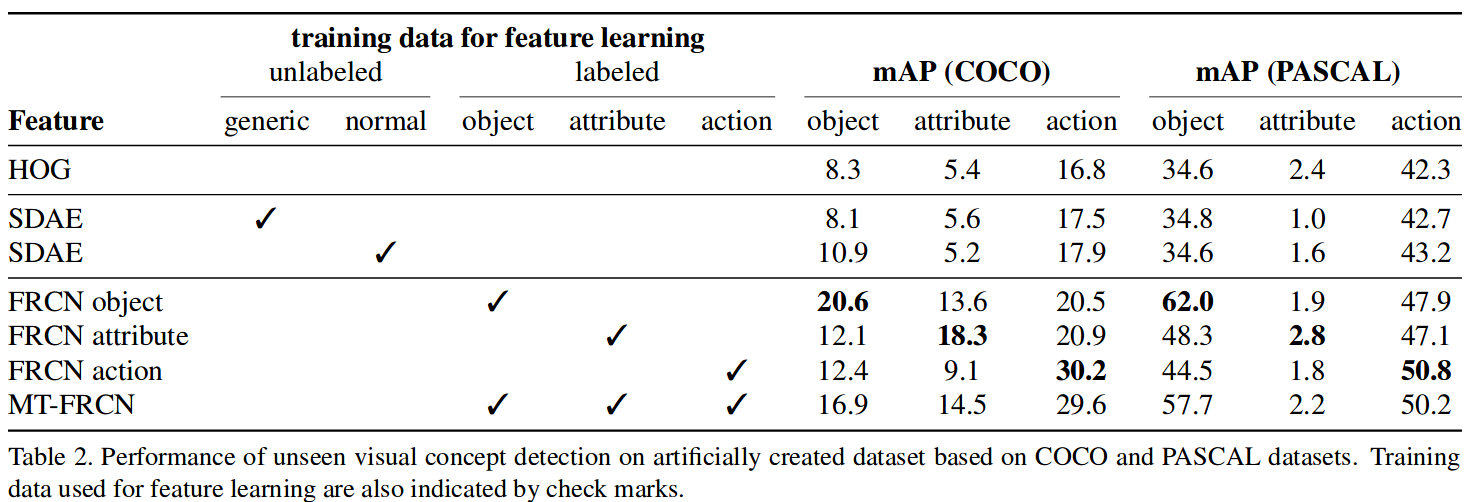
验证说明了当使用多个任务联合训练时能够提高模型对于未知concept的detect能力。
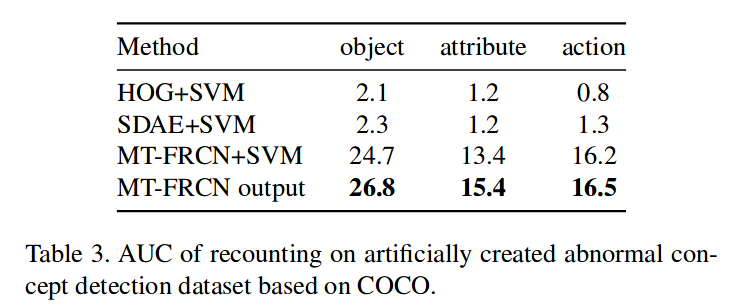
而通过比较KDE倒数(分类分数要同时大于0.1)对于unseen类别的异常分值,来评价对于未知异常的发现能力,显然MT-FRCN比baseline都要好。
5. Discuss
这是第一篇探索异常检测与解释的论文,采用了多任务FRCN,并在另外更大的数据集上进行预训练以提取target数据集的特征,通过KDE进行数据集的特征统计学习以发现异常。有一定的未知类异常发现能力,较为鲁棒。当时算力限制做了一些例如分grid,特征可能的过多压缩,还要没有使用运动特征等,都是可以进一步探索和改进的。
但是异常检测数据集UCSD\Avenue等缺乏对于异常丰富的标记,也比较小,不利于做更多的工作,不知这会在ShanghaiTech和UCF-Crime上表现会如何呢?
CVPR 2019的object centric也是类似的使用了整个数据集的特征来做统计,获得分布之后来做异常分值计算。其实更进一步地,将VAD和数据挖掘中的ML结合,是否会有更多可能性呢?