CVPR 2019: 物体为中心的自编码器与伪异常的视频异常检测
1. Overview
一直以来,深度学习的视频异常检测大多局限于做帧级别的模型。但是如果仔细想想,在当前所有的数据集下,异常都是前景产生的,而前景是稀疏可分的,那么基于前景对象进行异常检测应当能起到一定的作用。
文中作者认为,可以利用分类的方法用于异常检测,构造一种类似监督的方法应该能够提高模型的表现能力。所以借鉴了图片无监督分类,利用聚类产生伪类标,以伪类标进行类似有监督的方。
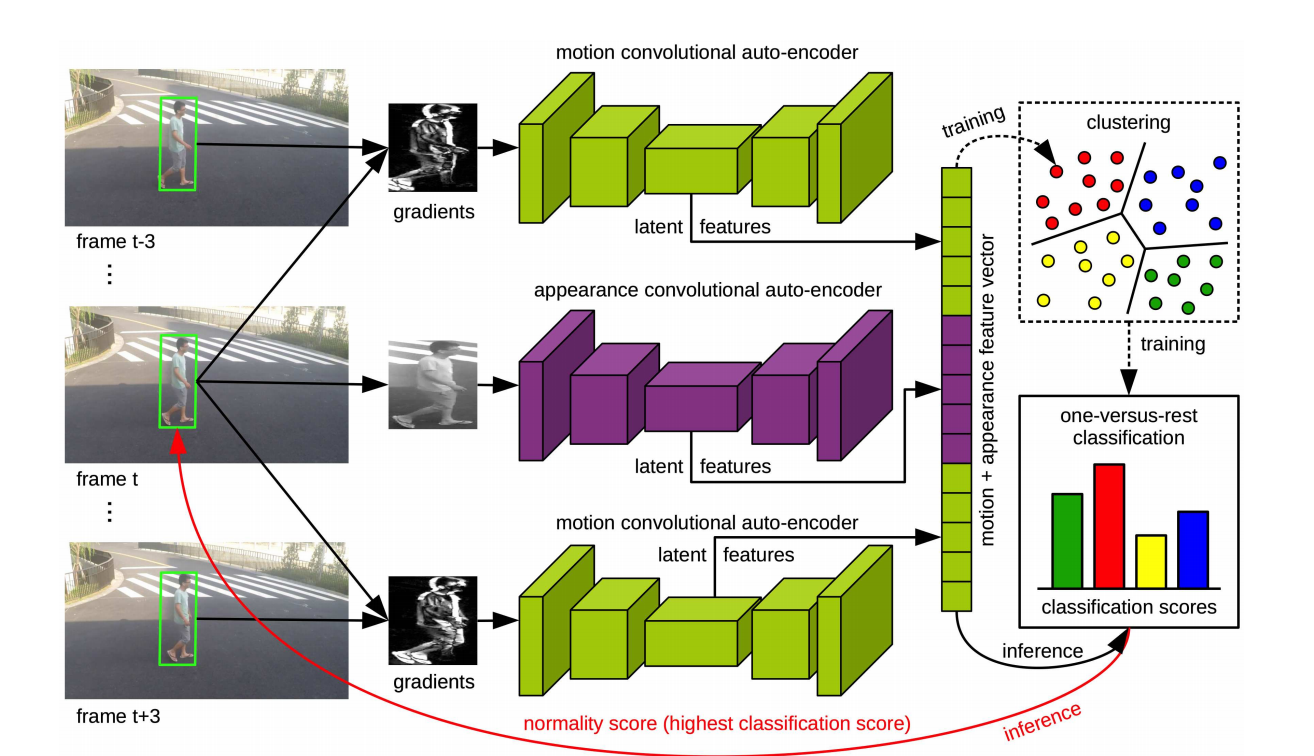
模型整体框架如上图所示,利用SSD(single shot detection)逐帧检测前景物体。利用检测的boundary box 截t,t-3,t+3的帧中的该对象,t只取灰度图,然后对于 t-3 与 t+3 时间下进行计算与 t 梯度变化,然后这三个图像分别进行AE获取隐特征,然后对三个特征concat形成视频帧t的特征向量。获取特征向量后进行k-mean聚类,能够获得K个聚类,产生K个1-vs-rest的二分类器,最大分类分数即为异常分值,以此发现异常。
Pineline 可以概括如下:
- object-detection
- object based feature extraction
- K-Mean cluster
- Train 1-vs-rest SVM
- Inference -> Anomaly Score
2. Model Design
2.1 SSD
选择SSD,因其快速且准确,能够有达到13fps,由于FPN能够检测到小物体。但我对于采用SSD这种有监督的模型进行object proposal 持保留意见,这是否就是暗含了异常前景物体就是已知类的假设呢?(如果采用结合运动与纹理的物体提出是否会更合理?当然可能效果上比不上SSD。)
2.2 AEs
模型里训练了3个 AutoEncoder(其实第一个和第三个保留一个就行了吧,当然分开能够相对串行要快一些),通过 逐像素的MSE 的重构 loss进行自监督的特征提取。大概是为了做到实时的效果,AE的结构也很简单,encode 3个卷积层,decode也是,尽力去减少计算时间。另外采用了灰度图而不是RGB,采用gradient而不是optical flow,都是为了减少计算时间,同时对于异常检测而言,色彩并不是很重要,光流计算麻烦,而梯度变化能够表示一定程度的运动,更重要的是在运动幅度不大的时候,可以剔除背景。
2.3 1-vs-rest SVM
采用了K个1-v-rest 的二分类SVM,对于每一个cluster来说,其他cluster就是伪异常,那么对于每一个聚类可以训练一个二分类器,将自身与其他聚类分开。经过训练之后,就可以得到的决策边界,负样本会比真正的异常样本要离中心更近。
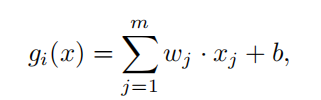
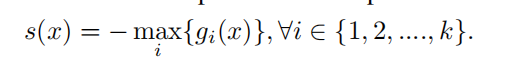
s(x)就被认为是异常分数。
2.4 Details
- 对于两个物体bbox重叠的情况,取交集,异常分值给交集。
- 对于一帧内有多个异常物体,异常分值取最高的物体的。
- 对于输出的分数进行了时序高斯平滑。(这个能够去掉过多的分数波动,会一定程度上提高异常初期和后期的检测,但是这会导致模型比较时的不公平)
3. Experiments
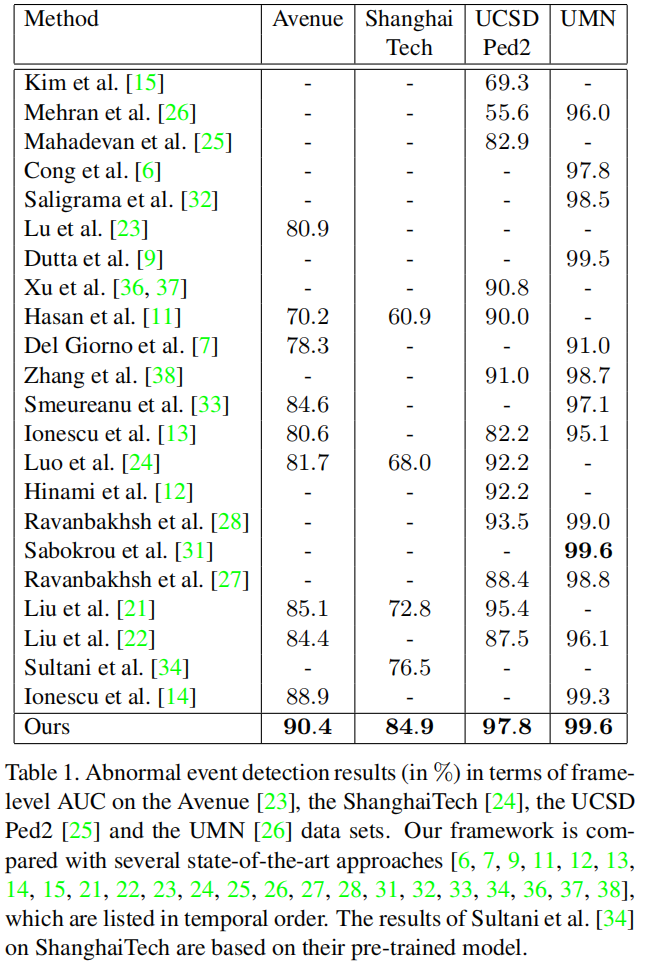
本文最能拿出来说的,就是这个AUC比较,在Avenue和ShanghaiTech上都刷出了新高。
对此,我认为的是,Avenue数据集是平视拍摄的,存在这、前景物体的尺度变化,而ShanghaiTech是多场景的数据集。尺度变化和跨场景对于传统给的帧级别的算法都是困难的,但是对于物体级别的方法而言,这两个问题已经影响不大,采用固定的物体尺寸就无视了尺寸变化问题,截取物体就剔除了绝大部分背景,同时本文使用了gradient作为运动特征,进一步削减了背景的影响。
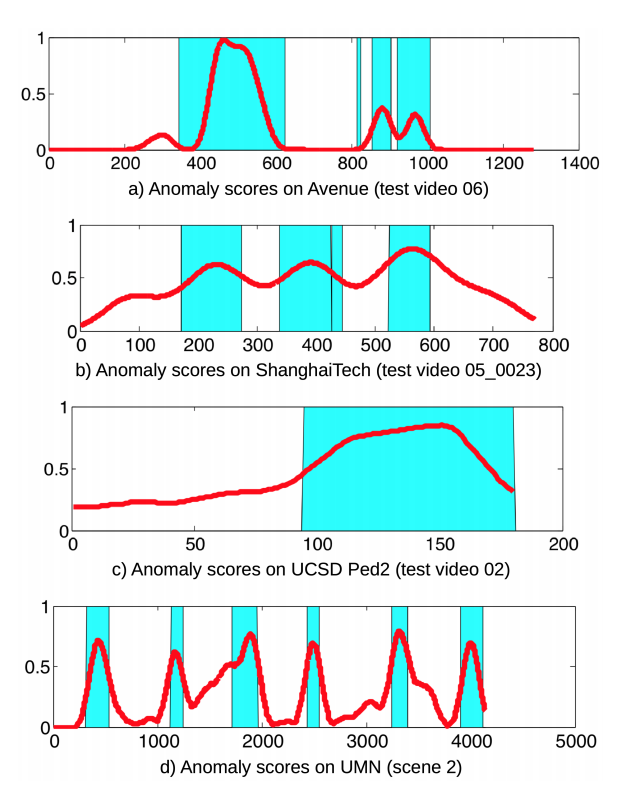
观察异常分值,峰谷明显,一定程度上能够直接采用时序的异常检测或者简单给定阈值检出异常。
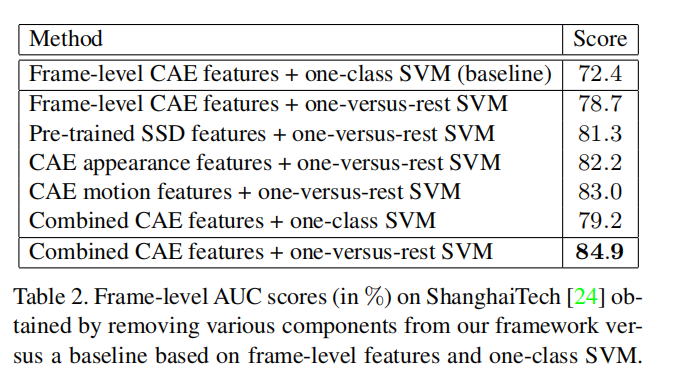
在消融验证中,我们可以看到通过K个的1-vs-rest的SVM能够明显提高异常的检测能力.
4. Discussion
- 这篇文章开启了基于物体的异常检测,把异常检测与无监督图片分类联系在了一起大幅度提高了模型的表现能力,但是也好像同时宣布了这些数据集要到头了。
- 还是需要延迟3帧才能检测异常
- 忽略了物体的位置/场景,忽略了全局信息,忽略了物体间的关系。