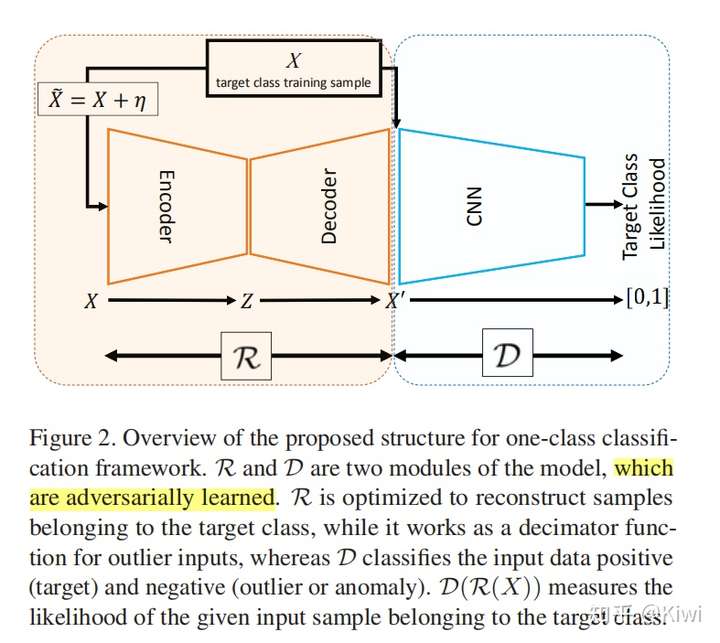
重构方法是最传统的异常检测方法
异常检测概述 II Review of Anomaly Detection, Part II : VAD Taxonomy
本文在part I拖更了数个月,终于抽空写完,本文相对于上篇,更注重对于最近的方法研究进展的探索,评判。视频异常检测是一个相当偏向应用的子方向,其中相当多的进展,其实并不是本方向的探索,多是“拿来”相关方向的进展,然后用于本方向,然后修改下,就成了本方向的进展,所以方法相当丰富,也让人一时眼花缭乱。
这么多年的尝试,但是怎样的方向才更有研究的价值,且但当涉猎,见见往事。
大家且读且评,一家之言,望不吝斧正。
异常检测概述(一):An Overview of Anomaly Detection Part I
0. Definition
视频异常检测,但从名字来理解,是从视频为基本的数据来源,发现其中的异常。
异常为何?异常不以为着危险,而根据[5]所说异常(离群点)是an observation “deviates so significantly from other observations as to arouse suspicion that it was generated by a different mechanism.”(一个观察结果严重偏离其他观察结果,以至于引起怀疑这个观察结果是否来自于不同的机制)。
由[4]中所述,异常是指不符合预期的模式。那么预期来源是什么?预期的描述可以有多个来源,来自专家知识编写的规则,来自数据驱动,还有两者之间的结合数据和专家知识建模。
由[2]所述,视频异常检测是指发现数据中的异常模式或者运动,而这些异常的模式和内容是被定义为非频繁或者是罕见事件。
1. Taxonomy
本文结合[1] [2] [3],对现有的视频异常检测领域的方法进行分类整理。
- 根据视频的主体的对象,可以分为群体场景(Crowd Scene)和非群体场景(Un-crowd Scene)。

-
根据视频的异常是定义为狭义的危险、违法犯罪 [7,11],或是广义的不符合训练集(历史)规律分为real-world,和非real-world(虽然后者一般不会提这点)
-
根据[1]监督信息的情况,可以分为
- 有监督:如[7] [11],对真实情景下的异常分类收集,产生一个较大的数据集,并根据数据集中对于异常与正常的差别进行有监督训练得到模型;[7] [11]都贡献了一个比较大的真实异常数据集,并且其中的异常被狭义理解为危险、暴力、犯罪等。
- 半监督的rule base方法:通过对训练集进行观察,生成规则,根据规则检测测试集中的异常;这种方法在解决虽然容易理解,但是较高的记忆和计算复杂度限制了其使用。
- 半监督的model base 方法:通过建立模型来表示正常行为,对于异常行为,其产生的表示应当与正常产生一定的差别,从而使得正常与异常可分。(但是这种方法对于非异常但是没出现过在训练集中的事情,容易误报,实际应用可能需要较大的训练集来避免这种情况。)
- 无监督方法:通过使用统计属性来区分这些没有标记的数据,快速没有使用先验信息。但是需要话费时间来对数据记性处理,依赖于异常行为足够的罕见。
有监督默认了 WDAD (Well Define Anomaly Distribution)假设,而半监督默认WDND (Well Define Nomal Distribution) 假设,而这两个假设能否在使用的过程得到保证,使这两种方法可行的前提。
- 根据使用的特征又可以分为光流(运动特征)、帧(Appearance)(stacked、切块)、压缩视频帧(motion vector residual)handcarfted features(HOF、HOG)、频域、轨迹
2. Reconstruction
Reconstruction,实际上就是对于输入的帧进行降维,通常后续伴随着恢复维度,以重建的图像与原来图像的差别作为异常检测的分数和定位的依据。最common的就是PCA降维,或者AutoEncoder这些,但是对图像用FC层叠成的AutoEncoder,参数量过大,不能加深,一般不用。(另外这些方法能够直接无视了图像的空间结构,毕竟输入到AE中的或者PCA中的都是flatten后的一维向量,没有上下,只有左右。)
2.1 Conv-AutoEncoder (CVPR 2016)[6]
*常用baseline
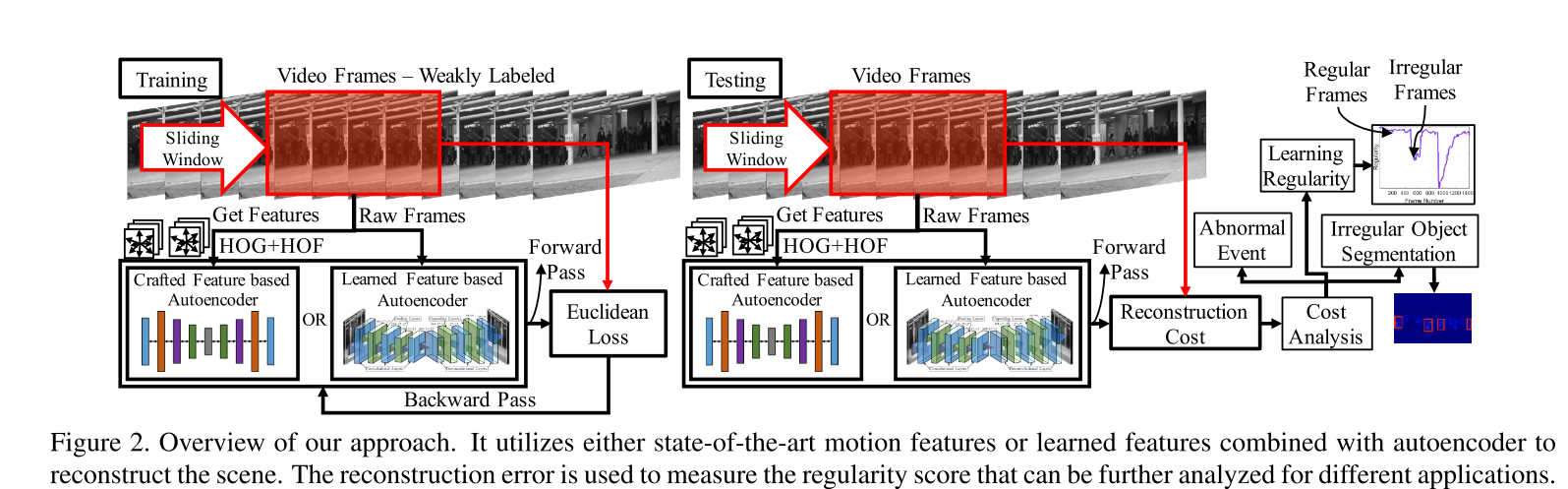
该文提出了两种方法:一种是基于handcarfted时空的局部特征(HOG+HOF),一种是基于CNN。handcarfted features模型省略不讲。主要讲deeplearning base的模型。
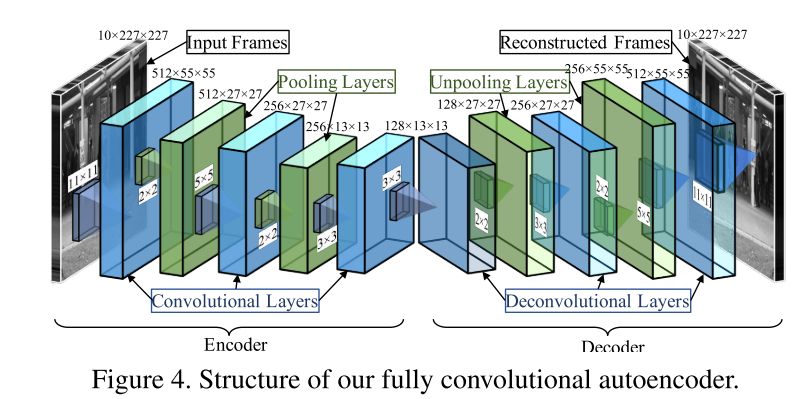
CAE网络结构采用的是,以一个sliding windows获取T个连续帧,然后输入到网络进行重构。其中T在采取5,10,20时,T越大收敛越慢,发现异常的能力越强。
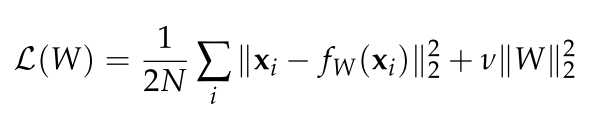
另外采用了不同的时间间隔取帧的方法来做数据增强,担心相对小的数据量不能够训练好模型,认为让模型能够对于不同的运动速度的重构能力(这样的速度变化,是否影响模型的表现,持保留意见)
文中的实现结果为:

但在[4]中模型对比时,对其复现结果为:
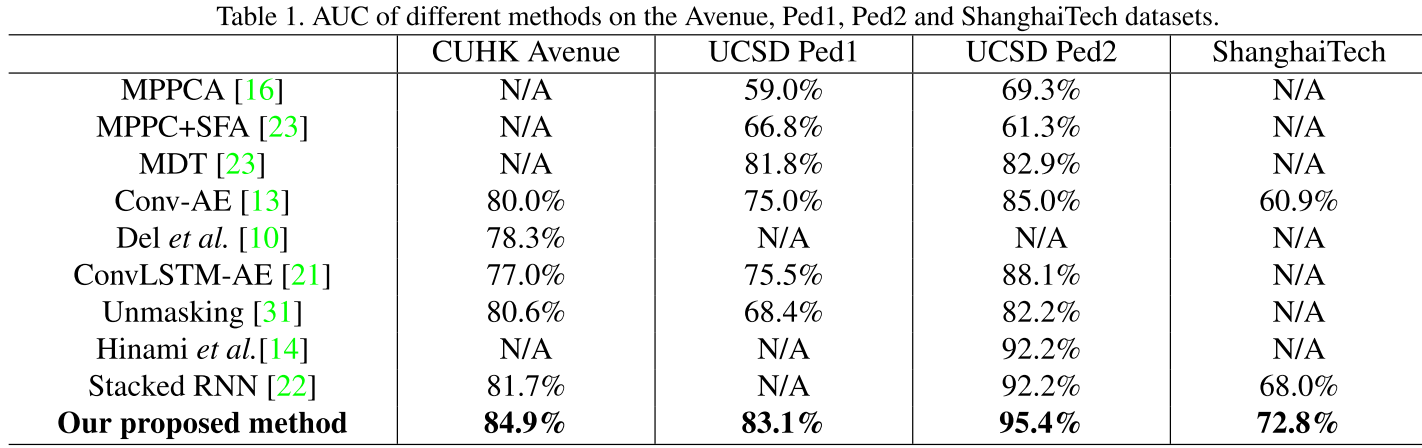
Reconstructed Model应该还有更多的衍生模型,针对此模型的改进与应还有很大的空间。
另外重构的好处在于,可以将输出重新输入模型,进一步放大重构差异,从而增加发现异常的能力。
2.2 Constractive-AutoEncoder (JMLR 2014)
Constarctive-AE与Conv-AE的loss很像,对于Weight的loss包括重构损失和隐层表示向量的正则。这种正则让模型尽管在最小化重构损失时,仍然能够保持对输入变化的低敏感度。
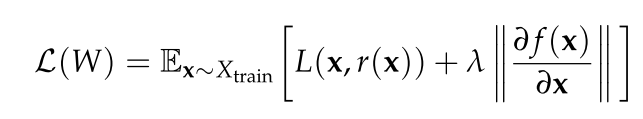
在只有三层FC的情况下,CUHK avenue中AUC能够达到83%~84%.
2.3 Adversarial-AutoEncoder
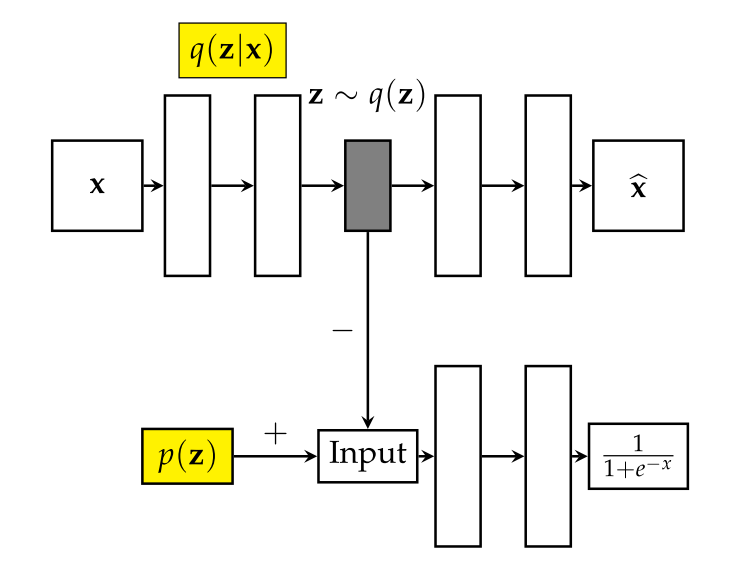
AAE的本质是通过GAN的方法,让AutoEncoder的隐层表示向量与p(z)相同。并且在这过程当中,改善了autoencoder的重构损失。让AE的隐层向量符合某种分布,而文中的分布是高斯分布,那么这个做法,实际上跟加了个BN层在中间,似乎差别并不大,有趣的是CAE和AAE中都没有用上BN?why?
没有获得其AUC的结果,但是将对抗引入到异常检测中,后续还有更多的发展。比如GANomaly.
2.4 Denoising AutoEncoder
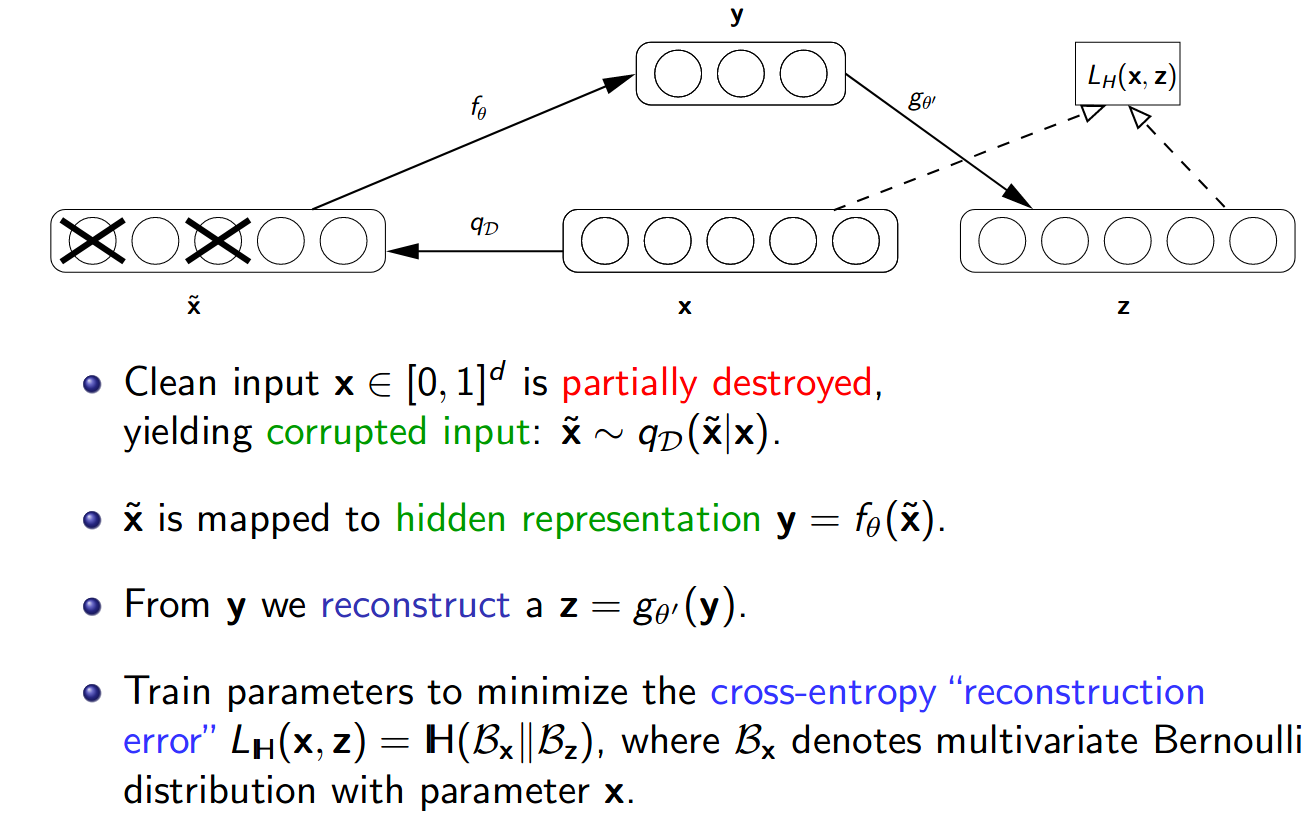
Denoising-AE是相当老的一篇论文,来自ICML 2008, 本质上就是对于输入的进行mask/noise,然后让模型学习去猜缺失的是什么,从而获得一个更好的数据集表示。

在CVPR 2018,此模型在衍生出了对抗学习单分类器。其实本质上是让模型对于数据集的某一种属性(表观结构)overfit,对于不符合数据集规律的个体,应当是错误还原,从而放大错误,得到更好的识别能力。
更多可以看我关于这篇写的论文笔记
2.5 Cross-Channels Prediction [13]
Cross-Channel Prediction的idea是来自于CVPR 2017的 ”Split-brain autoencoders: Unsupervised learning by cross-channel prediction“。这篇首先提出对于输入的图片划分为多类channel,相当于是多模态的信息,不同模态的相互image transfer。
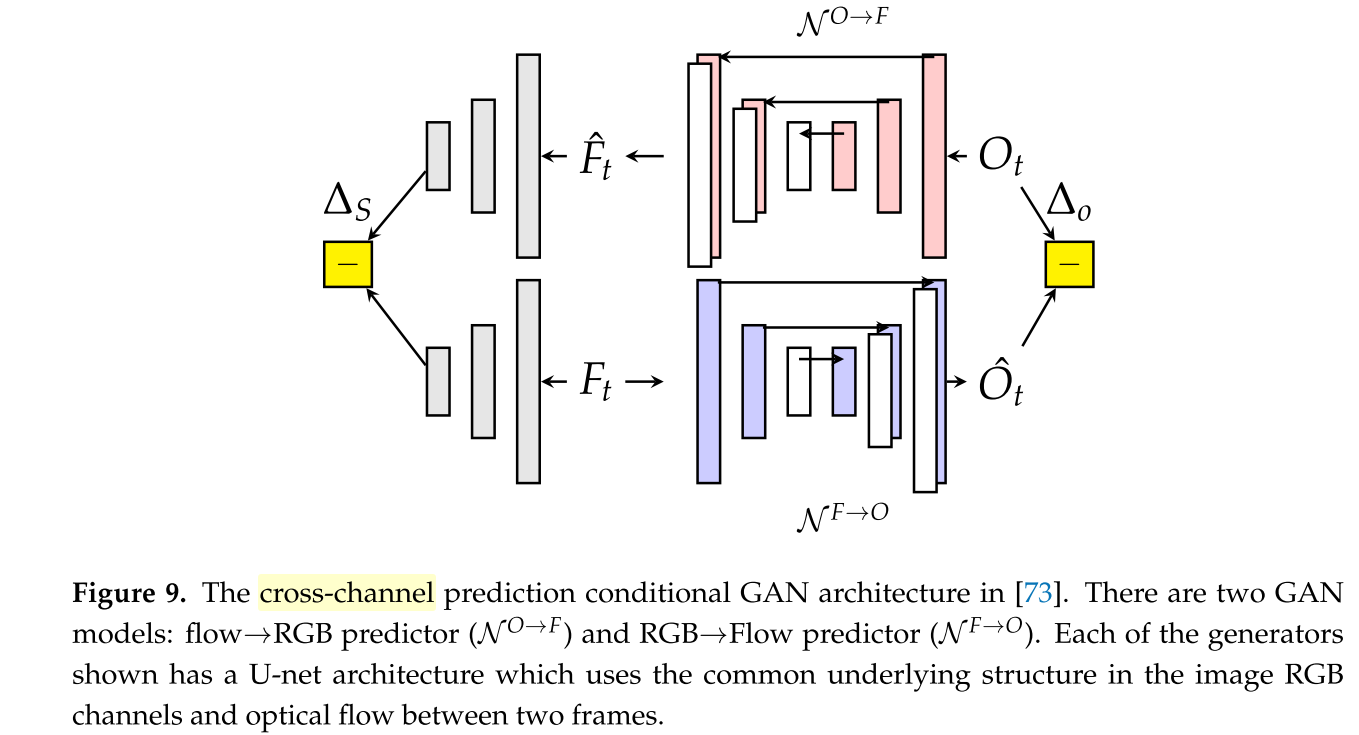
虽然名字说是预测,但我更认为,实际上就是跨模态的重构。[14]应用了[13]的思路,将帧切分为光流和实际图像,采用了U-Net作为base model做这两种模态的跨模态重构。这个模型并不是为了让图片生成的真实,而是为了让模型学会在训练集中这两种模态的转换方式。由于真实optical flow和预测产生的之间如果逐像素的比较并没有明显意义,这里采用了imagenet pretrained Alexnet来评价两者的语义差异。只采用了Alexnet前5层,然后语义损失是第5层输出的中两者的差,这两者的差的归一化就是语义差热图。而对于生成的图像,差值的归一化也产生了一个heat map,两者加权就产生了最终的异常热图。

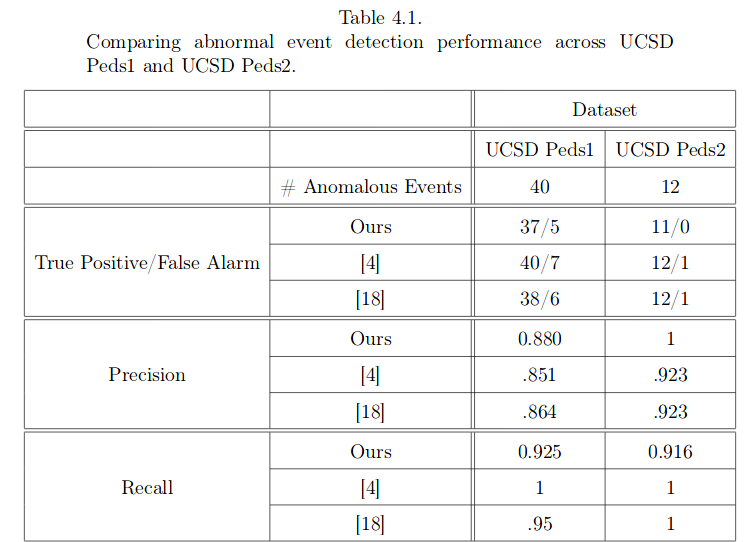
对于在UCSD上的[14]这个表现非常好,是我所知道的在UCSD的表现最好的结果,ped1 97.4%, ped2 93.5%.
但是这种方法有其局限性。对于UCSD数据集中,单个行人所占的size很小,并且通常情况下,人与人之间有足够的间隔,这样所产生的光溜能够很好的区分好各个行人,对于行人只需要生成黑色的行人姿态,基本不会产生很大的difference heat map。而且异常都是骑自行车的人、巡逻车这些,他们表观差异就很大,移动速度不同,那么就能比较明显的发现它们。对于CUHK avenue他们没有公布结果,大概也是结果不好不公布。
3. Predictive Model
重构模型侧重于对于图像的表观(Appearence)特征,即使有多帧,也只是将之当成把图片在channel上进行叠加,将时序体现在channel的顺序上,那么提取出的隐层表示向量实际体现的是多帧的融合结果,虽然依旧包含有时空信息,但在输入帧之外的信息都已经丢失,时空关系被弱化。
与之不同的是,有把帧单独出来,附加上以RNN或者LSTM等循环神经网络,隐层特征向量的结合RNN中的隐向量,如Composite LSTM [9] 如果加以生成历史帧或者预测未来帧的约束,能够输入的隐层特征向量获得一定的输入帧前后的时空状态信息。
3.1 Convolutional LSTM based AutoEncoder [10]

这是个和Conv-AE很像,CLSTM-AE但是在中间采用了LSTM,为了能够嵌套在CNN中,用上了Conv-LSTM而不是FC-LSTM,保持了空间结构的同时增强了时空信息的能力,相对于Conv-AE,有一定的能力提升,不过后续的复现结果好像并不是很好。
3.2 Composite LSTM Framwork [9]
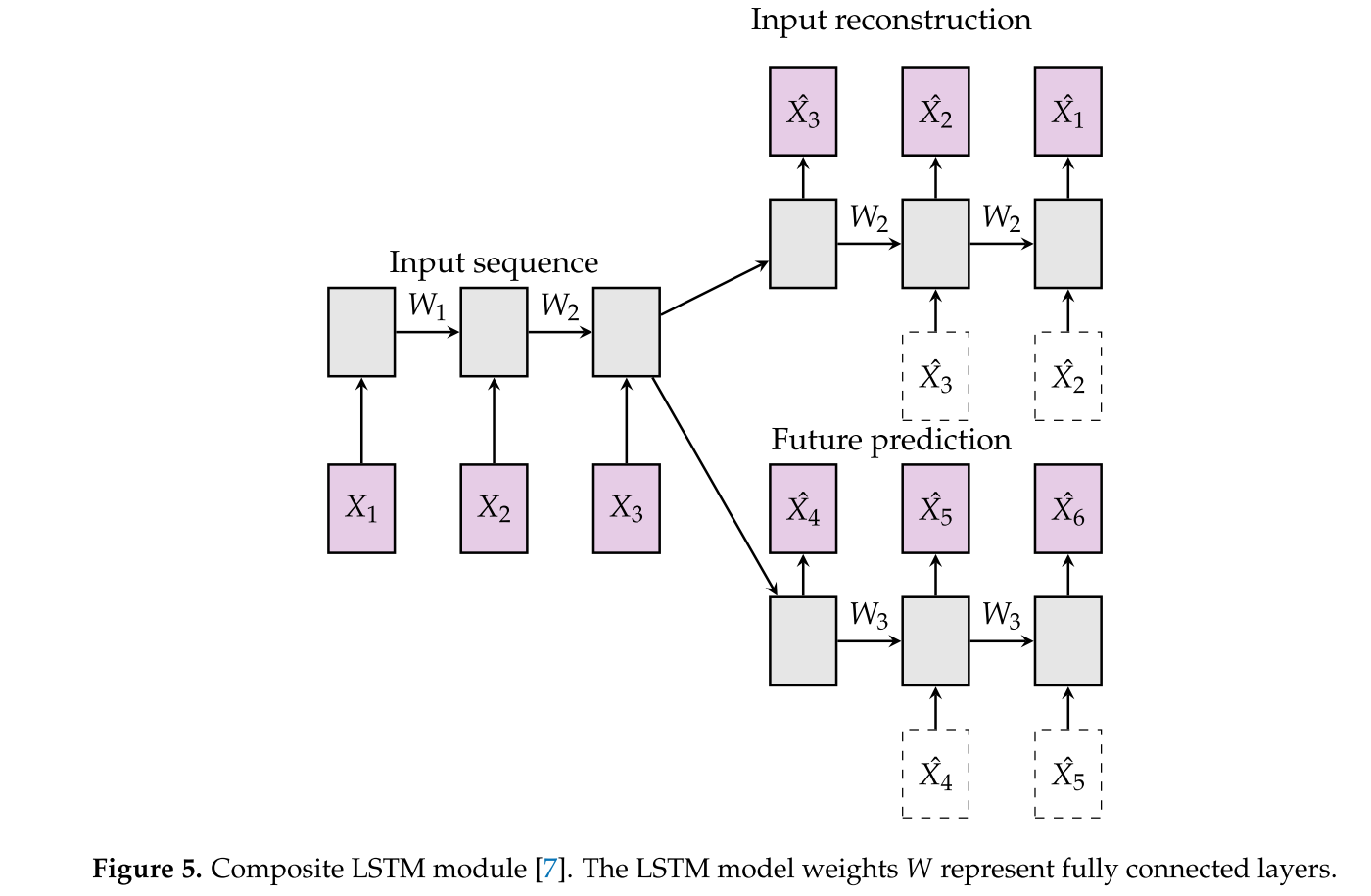
composite-LSTM在2015 ICML提出之后
3.2.1 Conv2D
4. Generate Model
4.1 GANomaly
4.2
5. Others
5.1 FCN Model (CVIU 2018) [12]
5.2 Compressed Video Based Model
在基于压缩视频的动作识别 谈过基于压缩视频来做视频系列的任务的好处。基于压缩视频做一系列的操作也不是什么新鲜事,早在13年就有人尝试在视频异常检测中做这些事情了[15]。历史原因,用的是核函数的SVM。
6. Sparse Coding Dictionary
6.1 Online Detection of Unusual Events in Videos via Dynamic Sparse Coding [17] (CVPR 2011)
[17]是CVPR2011年的论文,在没有deep model的时候李飞飞老师就提出了解决视频异常事件检测的方法。
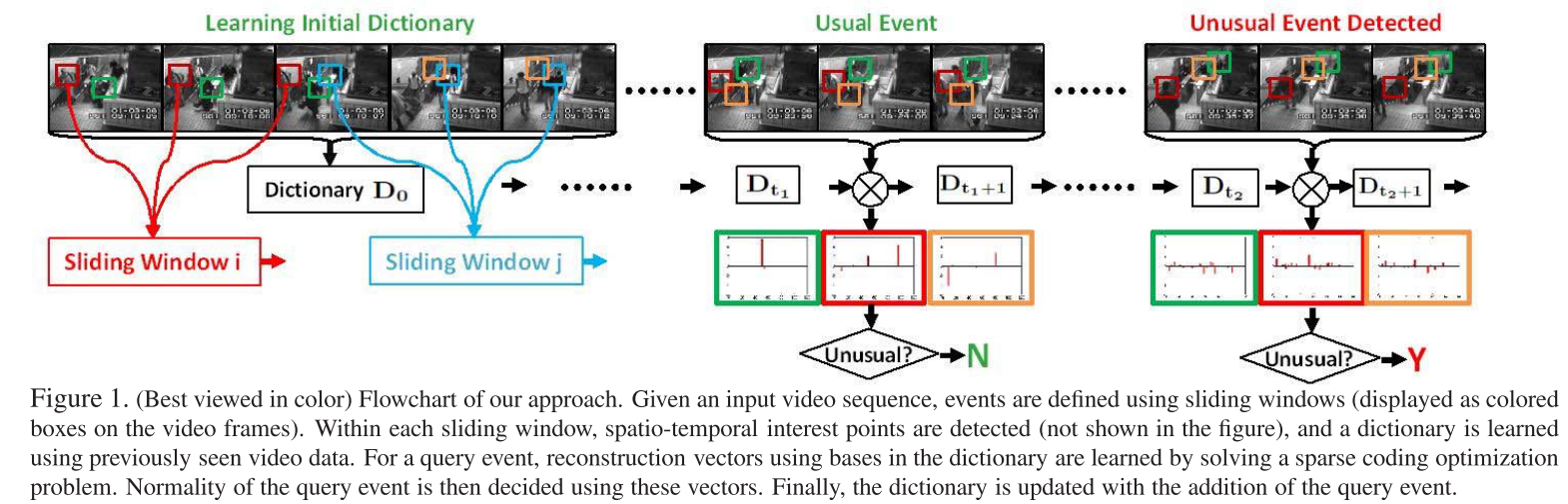
字典学习与稀疏表达
对于字典学习而言,希望能够通过在给定的小的数据集中学到一个字典,这个字典A,对于每一个输入x,A*$\alpha$能够最小化重构误差,重构出图像x,另外,我们希望得到的表示向量足够的稀疏,对于$\alpha$ 加上了稀疏的限制。稀疏与重构误差存在一定的trade-off。
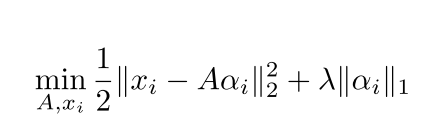
[17]中的做法是,利用sliding windows把一段视频划分为多个子事件,那么子事件内多个帧可以叠在一起,形成一个小时空方块,每一个方块之间应该存在着时空相邻相似,相离不相似,那么就应该在上面公式上再加上一个限制。
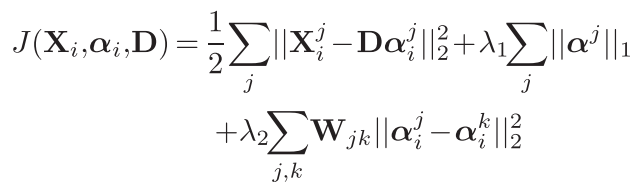
由此,对于W,采用了高斯RBF核函数。

文中很大一部分讲如何在小数据集上初始化字典D,然后online update。online update的时候希望能够让字典对于所有的数据集的重构损失最小,但是在online learning是不能够在接触到历史帧,那么这里的做法是利用$X_t,D_t,D_{t-1}$, 利用了类似SGD优化算法,步数越后,变化越小。
如何发现异常?
异常就是重构损失大于阈值的项,通过对图像切块,那么可以同时大概的定位出异常所在的位置。
6.2 A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework (ICCV 2017)
[18]相对于[17],后者是基于图片的HOF\HOG切割产生patches,而前者是切分CNN Enocder产生的heat map,而且是对单帧,切分也采用了多个size切分。对于heat map因为经过CNN后局部间特征混淆,已经失去了定位的能力,因此后者抛弃了patches间的距离差异,在[17]基础上将最后一个正则项改了。
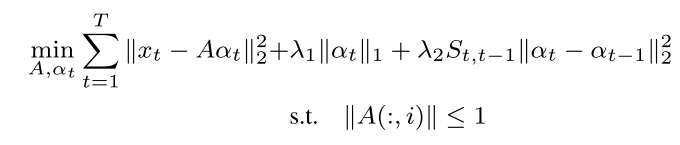
上式采用了SISTA(Sequential Iterative Soft-Thresholding Algorithm)进行更新,然后把这种算法魔改到stacked-RNN中。
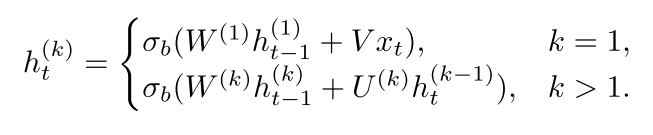
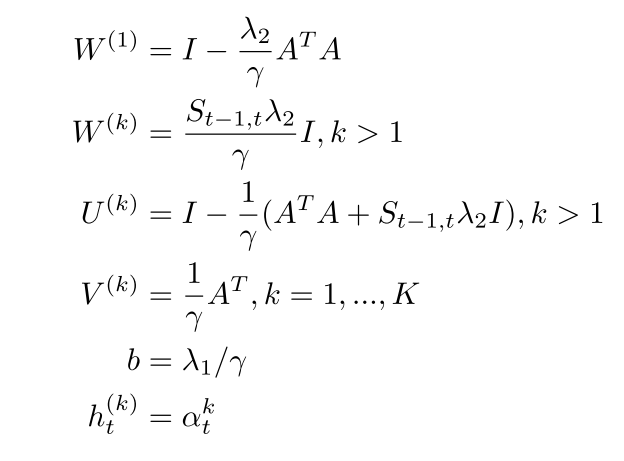
如果把Decoder的参数记作 Z, sRNN的参数(就是上式的参数)记为$\theta$ ,那么就可以得到一个和稀疏表达表达式很像的优化目标函数:
6.3 AnomalyNet: An Anomaly Detection Network for Video Surveillance (IEEE TIFS 2019)
今年较新的一篇文章,除了魔改了一个字典学习的优化算法到LSTM中,还提出了两个Motion Fusion Block和Feature Transfer Block,前者提出将视频端压缩到一张图片中,从而运动和表观信息就可以从以往的光流和RGB图变成一个Motion Fusion后的一张图。
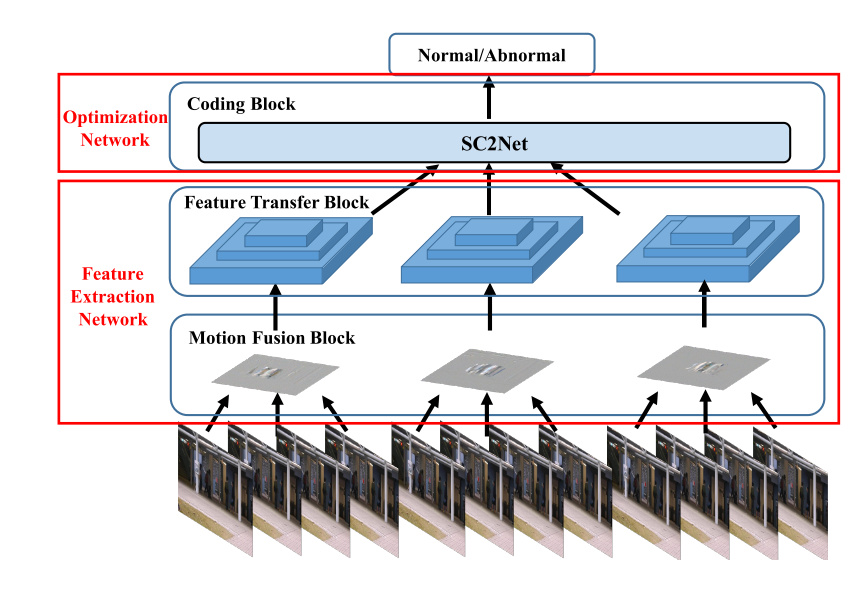
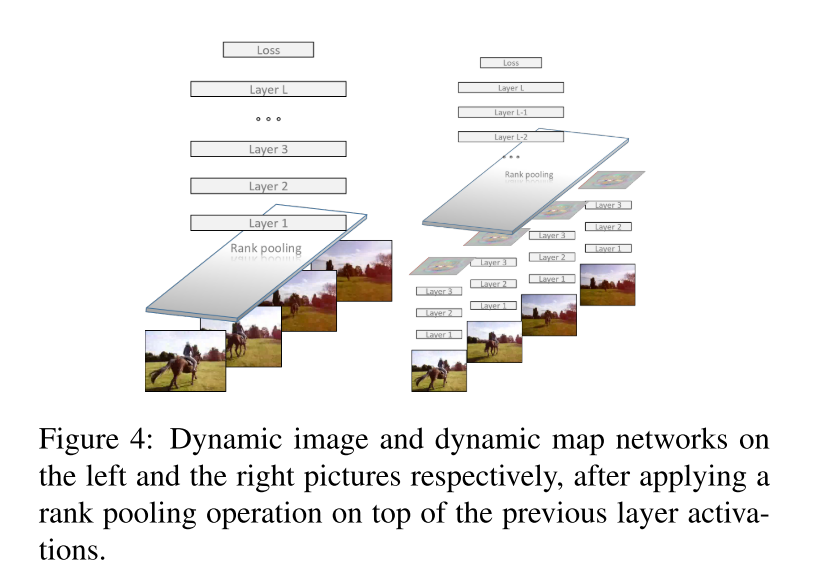
6.3.1 Motion Fusion Model (Dynamic Image)
这里使用的是CVPR 2016 的Dynamic Image,这会在7.5中细说,主要是采用了对连续帧的加权组合产生一张静止图片,并以此图反映视频的信息。文中采用了端到端Rank-Pooling近似Rank-SVM。

6.3.2 Features Transfer Units
6.Features Used
6.1 HOG / HOF
HOF HOG 事实上都是对于图像整体进行局部特征提取,注重与图像的边缘与光流。这些特征提取方法在CNN较浅或者训练不足时,能够提高模型对于连续的视频帧中物体与其运动的特征获取能力。在[6]中,认为这是在一个小的时空方块的低水平的运动信息。
HOG/HOF在现在基本没有人用了,作为一种在计算力受限的情形下的辅助手段,在计算力上升,并且深度学习网络可替代并计算得更好的光流。在本文用了imporved trajectory[8],来对于让获得的光溜是沿着轨迹信息(而[8]主要是通过引入光流与SURF特征点匹配来辅助评估摄像机的运动,主要是因为当初的光流计算结果受背景噪音影响的问题。对于手动提取的特征,去除后景保留前景,相当于Attention,这些deep model实际上也能完成)
6.2 Optical Flow
光流实际上是帧间差,对于帧间差。可以用opencv求,当然求的的不是逐个pixel的光流,而是像素块的光流,如Conv-AE加上对前景的发现将后景去除,能够获得更好的光流结果.
也可以通过使用FlowNet2 liteflownet 将这个过程变成end-to-end,但是就我个人使用的体验来说,Flownet2太重,可以占用一个12G的显卡,Flownet2的局部 FlowNetSD可以勉强用,liteFlownet在CUHK数据集上不错,但是对于
6.3 Frequency Field
6.4 Trajectory
6.5 Dynamic Image
7. Regular Score
7.1 Normed Difference Between Truth
经过模型(重构、预测)后得到的结果,求两者距离,然后归一化,得到的就是异常分值,1-就得到了正常分值。
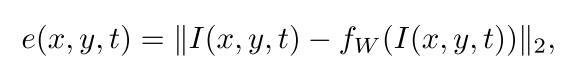
7.2 PSNR
通过模型得到的图片与实际的图片的PSNR值,多用于GAN产生的图片,同样使用时也归一化
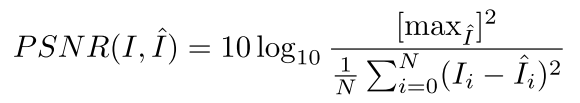
8. Trick
- 利用重构或者预测的输入输出域相同,将输出结果重新输入,(Stacked)
- 评判模型的是overfitting还是underfitting,如conv-AE中的做法,利用了这个模型训练了(比如有三个异常检测数据集 ABC 分为ABC\ BC\A训练,在A上测试,从而说明模型具有较好的泛化能力,并没有在某个数据集上overfit),不过这在其他方法上不见得能用
2. Blank Place
- deep learning based的模型,都是对于一个摄像头的数据集,对于此摄像头进行测试的。即使对于同一摄像头,如果有角度稍微变化,这个模型也可能失去效果(或者说需要重新训练)。这些方法就可能无法落入实地使用。如何让在场景相同,正常异常相同(比如同一场景下,不同角度拍摄获得多角度数据集)一个摄像头下的知识能够比较简单地迁移到另一个摄像头下,同时并不会有明显的性能下降。
- 在VAD中,视觉信息生而不平等。
- Domain Constraint: BN in VAD? Testing should(AdaBN)?
- GCN+Temporal+Spatial+Flow (Front Ground)
- 评判数据集中的异常的难度(利用无监督方法),什么类型的异常相当容易发现,什么异常是比较难发现,评判现有方法实际的缺陷,(提出更加具有挑战能力的数据集)
3. Related Topic
- Video Action Recognition / Detection
- Video Summary
- Video prediction
- Motion Descriptor
- Adversarial Learning
- Medical Image Segmentation
- online learning
- Sparse Coding & dictionary learning
- capsule networks
Reference
[1] Ben Mabrouk, A., & Zagrouba, E. (2018, January 1). Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Systems with Applications. Elsevier Ltd. https://doi.org/10.1016/j.eswa.2017.09.029
[2] Kiran, B. R., Thomas, D. M., & Parakkal, R. (2018). An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. https://doi.org/10.3390/jimaging4020036
[3] Chalapathy, R., & Chawla, S. (2019). Deep Learning for Anomaly Detection: A Survey. https://doi.org/arXiv:1901.03407v2
[4] Liu, W., Luo, W., Lian, D., & Gao, S. (2017). Future Frame Prediction for Anomaly Detection – A New Baseline. https://doi.org/10.1109/CVPR.2018.00684
[5] D. Hawkins. Identification of Outliers. Chapman and Hall, London, 1980.
[6] Hasan, M., Choi, J., Neumann, J., Roy-Chowdhury, A. K., & Davis, L. S. (2016). Learning Temporal Regularity in Video Sequences. https://doi.org/10.1109/CVPR.2016.86
[7] Baker, L. G., Specht, C. A., Donlin, M. J., & Lodge, J. K. (2007). Chitosan, the Deacetylated Form of Chitin, Is Necessary for Cell Wall Integrity in Cryptococcus neoformans . Eukaryotic Cell, 6(5), 855–867. https://doi.org/10.1128/ec.00399-06
[8] Heng Wang, Cordelia Schmid. (2013) Action Recognition with Improved Trajectories ICCV 2013
[9] N. Srivastava, E.Mansimov, R.Salakutdinov; Unsupervised Learning of Video Representations using LSTMs; ICML 2015
[10]Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In Proceedings of the14th International Symposium, ISNN 2017, Sapporo, Hakodate, and Muroran, Hokkaido, Japan, 21–26 June 2017; pp. 189–196.
[11] F.Landi C.Snooek R.Cucchiara; Anomaly Locality in Video Surveillance, http://imagelab.ing.unimore.it/UCFCrime2Local
[12] Mohammad Sabokrou⁎,1 ,a, Mohsen Fayyaz1,b, Mahmood Fathya, Zahra. Moayedc,Reinhard Klette; Deep-anomaly: Fully convolutional neural network for fast anomalydetection in crowded scenes ,https://doi.org/10.1016/j.cviu.2018.02.006
[13] Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 1, No. 2
[14] Ravanbakhsh, M.; Sangineto, E.; Nabi, M.; Sebe, N. Abnormal Event Detection in Videos using Generative Adversarial Nets. In Proceedings of the IEEE International Conference on Image Processing (ICIP) 2017, Beijing, China, 17–20 September 2017.
[15] S.Biswas, R. Venkatesh Babu; REAL TIME ANOMALY DETECTION IN H.264COMPRESSED VIDEOS 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG)
[16] Bin Zhao, Li Fei-Fei Eric P.Xing; Online Detection of Unusual Events in Videos via Dynamic Sparse Coding Bin; CVPR 2011
[17] Weixin Luo, Wen Liu, Shenghua Gao; A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework, ICCV 2017
[18] Joey Tianyi Zhou, Jiawei Du, Hongyuan Zhu, Xi Peng, Yong Liu, Rick Siow Mong Goh; AnomalyNet: An Anomaly Detection Network for Video Surveillance, IEEE TIFS 2019
[19] Hakan Bilen†, Basura Fernando‡, Efstratios Gavves, Andrea Vedaldi† Stephen Gould. Dynamic Image Networks for Action Recognition,CVPR 2016
[]