Denoising AutoEncoder的CNN+对抗版本
Adversarially Learned One-Class Classifier for Novelty Detection
1. Novelty Detection
Novelty Detection 字面翻译是新颖性检测。本质上就是发现输入的新的对象/模式,其实就是Anomaly Detection,不同名字而已。发现一些与目标类某些方面存在差异的现象。异常类型总是缺失的或者是不能被列举的,所以要区分开正常和异常,通过直接训练端到端异常分类器是不可能完成的任务。

2. 本文主要idea
既然没有办法去找到异常的样本,那么通过更好的描绘正常样本的边界(或者准确来说是正常的边界),异常应该能更好的被发现。那么怎样去描绘这个正常样本的边界呢?
首先在实际的场景中,输入的图片是可能会有各种噪音的(光照、摄像头等等因素),所以一个健壮的分类器应该能够在噪音图片中获取到信息,当然绝大多数的训练数据都是高质量的,那么可以通过自己加噪音来增强数据,同时这也增强分类器对于正常样本的边界的描绘能力。
单纯加噪音只是数据增强的technique。除此之外,本文用了在VAD常用的方法,通过Conv-Autoencoder来重构图像。正常样本应该能够在训练中,Encoder知道如何抽取合适的特征以让Decoder重构。非训练类,Encoder抽取的特征会较差,Decoder重构就会更差,误差逐层放大,那么非训练类经过这个AutoEncoder得到的结果就会和原图片差异较大。通过重构的差其实就可以作为一个指标来判断是否是异常类,不过这可能有点弱。

本文却在最后加上了一个Discriminator,意在通过类似GAN的对抗训练方式,一方面增强图片重构能力,另一方面增强分类的能力。将AutoEncoder训练成一个健壮的DeNoise-AutoEncoder,让denoise效果能够和原图片相近,让分类器分不出这图片是原图片还是经过加noise然后再去noise的图片。
这种操作能够产生针对目标类的特征提取与还原,并且在训练集上确保了这种操作不会被分类器所发现,也就是这种方法不会对后续判断造成误差。期望的是,测试集类似训练集,重构的误差较小,那么对于分类器的判断不会带来太大的误导信息。

但是对于非目标类的内容,会带来更大的误差,毕竟经过针对目标类的特征和还原的AutoEncoder,应该是会带来更多的噪音信息,这样就能给分类器一个更强的指示,就更能区分开这两者。
3. 具体模型
模型主要包括有重构模块和生成模块。
3.1 重构模块结构
由于重构模块是训练来重构目标类的样本的,你那么对于异常样本来说,应该重构损失是高的。
首先需要强调的是,这里输入的图片是经过噪声处理的图片,输入的噪声是基于正态分布1543490309523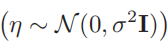 产生的。当然图片在加噪声前先得做个归一化。
产生的。当然图片在加噪声前先得做个归一化。
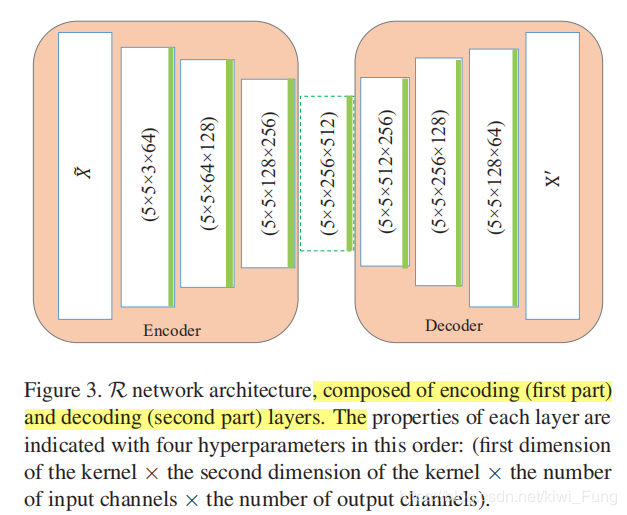
本文没有采用U-Net来重构图片,也没有采用Pooling来下采样(为了提高网络的稳定性),只是一直在做卷积,以5x5的卷积核在做Encoder和decoder。Encoder中采用了lrelu的激活函数,而在Decoder则用了relu,最后一层为了输出当然采用了tanh。同时所有的卷积层都用了BN来增强稳定性。(结构根据应对的样本的难易会有所调整)
3.2 鉴别模块结构
鉴别模块其实和Encoder很像,就是多了最后的一个目标类相似度评判。
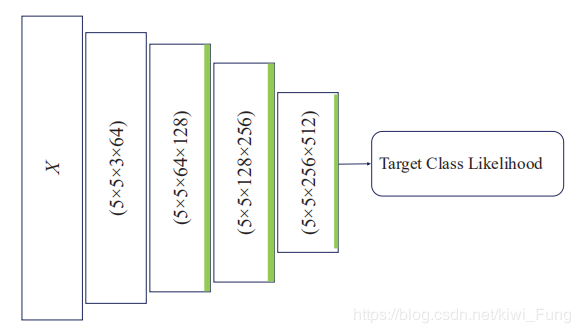
就是最后将特征展开一维进行FC(这个FC只需要一个单元,输出的是相似度,自然采用了sigmoid)。sigmoid前的输出值也会保留,后面有用。
3.3 对抗训练
传统的GAN的方法是需要对于原始图像 X 和隐特征向量 Z 做对抗性的mini-max竞争:

也就是使得最大化鉴别器的对于隐特征向量生成的图片的识别能力,最小化生成图片被识别的可能。就是要让隐特征向量G(Z)变得服从$p_t$分布。
由上面的2和3.1 3.2 我们可以看到我们要做的和GAN有些差别,需要的是让

这个$X’$其实就是R(X+n)产生的denoise重构的图片。也就可以写成:
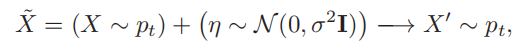
对于重构模型损失就可以写成:

其中$L_R$很简单: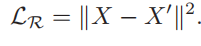
L_R+D可以仿照GAN写成,对于鉴别器而言,其Loss就是$L_D_fake+L_D_real
4. 实验结果
实验是基于MNIST,UCSD ped2, CalTech三个数据集做的。公布的代码只包含了前两者的实验过程。

似乎这样训练出来的D(X)能力就不错了。D(R(x))相对来说帮助的效果似乎并不见得很好,微乎其微,甚至可以当作实验误差。
本文有趣的地方就是用了VAD的UCSD的ped2。这个数据集大概被刷到了AUC 95.4%,本文没公布这个结果,只说了EER达到了state of art,这个我跑一下再比较结果。

5. 可能改进的地方
- 我们可以看到文章的改进效果并不是非常大,应该还有提高的空间。
- 由于训练是两个优化器进行的,什么时候终止训练,对于测试的效果是有影响的。本文采用的是当重构损失降到收敛就停。R+D两部分的训练方式的改进会对结果有一定的变化。两部分的共同训练,如果过早停止的话,那么权重还没调好。过晚停止的话就会导致鉴别器太强了,重构模块的损失将会主要是鉴别损失。所以我们会看到文中的设置鉴别器和重构采用的模块都是类似的,为的应该就是避免某一块过强。
- 实验中尝试过混进异常内容进训练集,10%的outlier并没有导致模型的严重下降,EER只是下降了1.3%
- 一个VAD的数据集,不需要时序,直接对帧进行操作就能够判别出异常。或许也能说明,这个数据集啊,其实时序信息好像并不见得很重要?Maybe to weak.
- 会不会是测试集实在对抗性太弱了,如果提出更强的对抗性的样本能否让论文结果更加solid?