关于服装识别的文章
CVPR 2016: DeepFashion: Pwoering Robust Clothes Recognition and Retrieval with Rich Annotations (健壮有效的有大量标签的服装识别与检索)
Abstract:
- 提出一个大规模的数据集,超过80000张图片,被大量标记的。服装类型的模型评测数据集。而且图片拍摄于于多个场景(店拍、街拍、消费者自拍)/多种姿势
- 提出一个FashionNet的模型,通过预测服装特性和标志来学习衣服的特征。
1. Background
1.1 服装识别算法要解决的三个问题:
- 服装在款式、纹理和裁剪上有很多的变型,让已有的系统难以解决预测问题。
- 服装的很容易就变型或者叠合在一起。
- 服装图片在不同的环境下会有很多大的变化,比如线上的图片和自拍相比。
1.2 数据集
- 别人的数据集各种不足:
- 仅仅含有后者的某一些部分,而本数据集deepFashion都包含了(服装的语义特征、服装的位置、不同场景下的服装相关性)
- 给更多标志/特征部分的位置
- 于是提出了更大数据集,更多的标注。。。。还小心的确定了为三大任务提供评判数据集和验证协议
- DeepFashion数据集描述
- 两倍于前人数据集大小,shop/consumer images
- 丰富标记的服装类项,50类,1000个描述特性和标志
- 包含着30000张多姿势/多源(shop/consumer)的图片对。
- 数据集的产生方式
- 来源于网上的电商网站,和客户评价的网站收集到的关于391482个服装类别的1320078张图片。
- 谷歌搜索的服装图片,12684次不同的搜索,总共1273150张图片。
- 合在一起清洗。通过利用AlexNet的fc-7的输出比较来分辨出相近/一模一样的复制的图片,删除复制后得出的图片经过人工的标记来删除低分辨率/图片质量或者根本不是服装的图片。
- 最终得出800K张图片
- 图片标注
- 大量的特性:重要的类别信息来认出或者表现楚大量的服装项。
- Landmarks:利用服装特定位置的标记来处理解决服装变型或者时姿势的多样。借助局部的采样来得到多个局部的信息,并将局部信息组合,形成局部特征图,那么就可以利用局部的特征来确定是否为相近的类型。
- Consumer-to-shop pairs :用于克服不同场景下的图片的识别能力问题
1. 生成类别与特性列表:源于用户搜索(这绝对是跟电商网站合作了,拿到了资料)将搜索的adj+n中将名词提取,然后将adj合并一起,提取前1000个高频的作为特性。特性被氛围5个类别,分别为:
1)纹理 2)面料 3)形状 4)部分(?上下装/全身装等等) 5)款式
2. 类别与特性标记:类别集大小适中(50类),类别标记是定义上是互斥的。每一张图片最多接收一个类别标记。对于1000个特性,特性多而且,每张图片可以有多个特性,不可控制。因此对于手工标记的特性标记进行重新排序。特别的,对于每一张图片,我们对比特性列表和对应的手工标记(数据搜集过程中获得的)将与特性列表匹配的认为是“fired”,枚举每组前10个特性1
2
3
3. _Landmark 标记_ : 一系列的服装的特征点,用于表示服装的结构。有些关键点可能重叠的
4. 对匹配标记:收集多源服装图片,去除噪声并且确保准确的对匹配。
5. 质量控制:多人标记并检测差异,结果发现有 0.5%需要重新标,标记准确性整体而言可以。
2. FashionNet
2.1 网络结构:
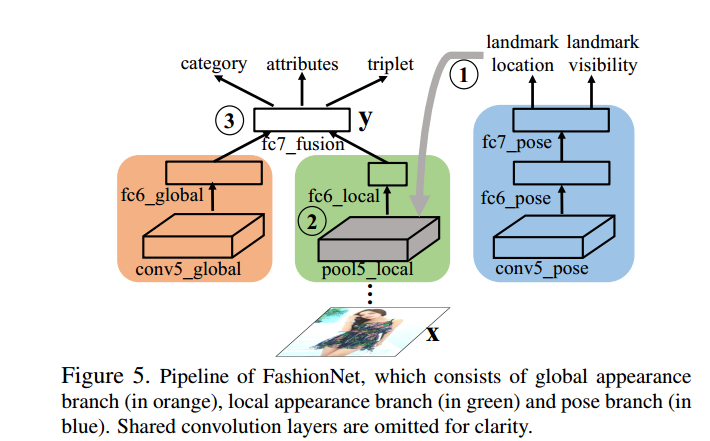
类似VGG-16,特别的,在倒数第二层卷积层之前都一样,就是最后一层卷积层,被针对设计用于服装(?。如下图所示,最后一层卷积层被替代为三个分支,红色以卷积层获取衣物的全局的特征,绿色以池化获取局部特征来实现衣服的标志的检测,蓝色的则是用来识别图片中标志位置的识别以及可视性。红和绿的输出都输入到fc7中产生出类型/特性/服装对。
2.2 Forward Pass
前传的过程分为三个阶段。
首先是服装图片输入网络,先传到蓝色部分,预测标志的位置,
然后第二步,检测到的标志都会被用于池化特征,获取不会因为变型或者折叠而变化的局部特征。
第三步就是全局特征和局部特征池化层进行一个融合输入fc7_fussion
2.3 Backward Pass
2.3.1 四种误差函数。
分别是
· 标志点的位置的回归误差
其中D是样本个数,$l_j$是实际标志点的位置,$v_j$是关键点可见性。
· 预测标志点的可视性的softmax误差/类别误差 将1-of-K的softmax损失分别记为L_visibility和L_category
· 特性的预测的交叉信息熵的损失
其中$x_j$就是表示第几张图片,那么$a_j$就是预测出来的特性向量。对于omega_pos和omega_neg两个系数,是由训练集当中pos样本和neg样本的比例。
· 三个一组的算是,pairwise的原图片与正负例图片三元组
这个triplet其实就是(X,$^+,X^-),后两者表示的是与X图片内的服装类型一样的图片和不一样的图片的三元组。d(·,·)就是距离函数,m是边缘参数,?怎么定的呢

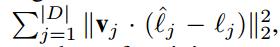
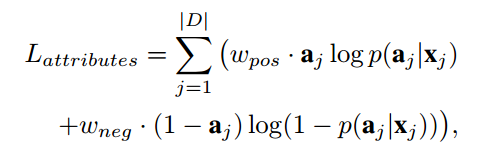
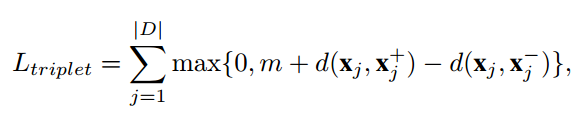
迭代训练策略:
FashionNet的整体损失函数是通过对四个函数的加权整合做出来的。
- 视蓝色分支为主任务,其他为辅助任务,给L_visibility和L_landmark 大权重,另外的小权重,然后训练
- 预测服装的类别和特性还有服装之间跨类别关系。这一步当中预测的标志点位置会被用来pool出局部特征。
重复以上两个步骤直至收敛。
landmark pooling layer
conv5的输出的featrue map和预测出来的landmark location作为输入进入这层中。不可视的landmark置为零,然后对于在landmark附近的区域用最大池化来获取局部特征。(那么预测出来的结果landmark的位置应该是介于0~1,可以方便还原成conv中的位置),这些局部特征图会被堆栈成局部特征图,不同的是,这里的pool是跨landmark获取的。
也就是说,从conv5的feature map中以多个标志位置截取出标志附近的多个小区间,池化出一个pool_local。
所谓landmark就像下面那样。

3. 实验结果
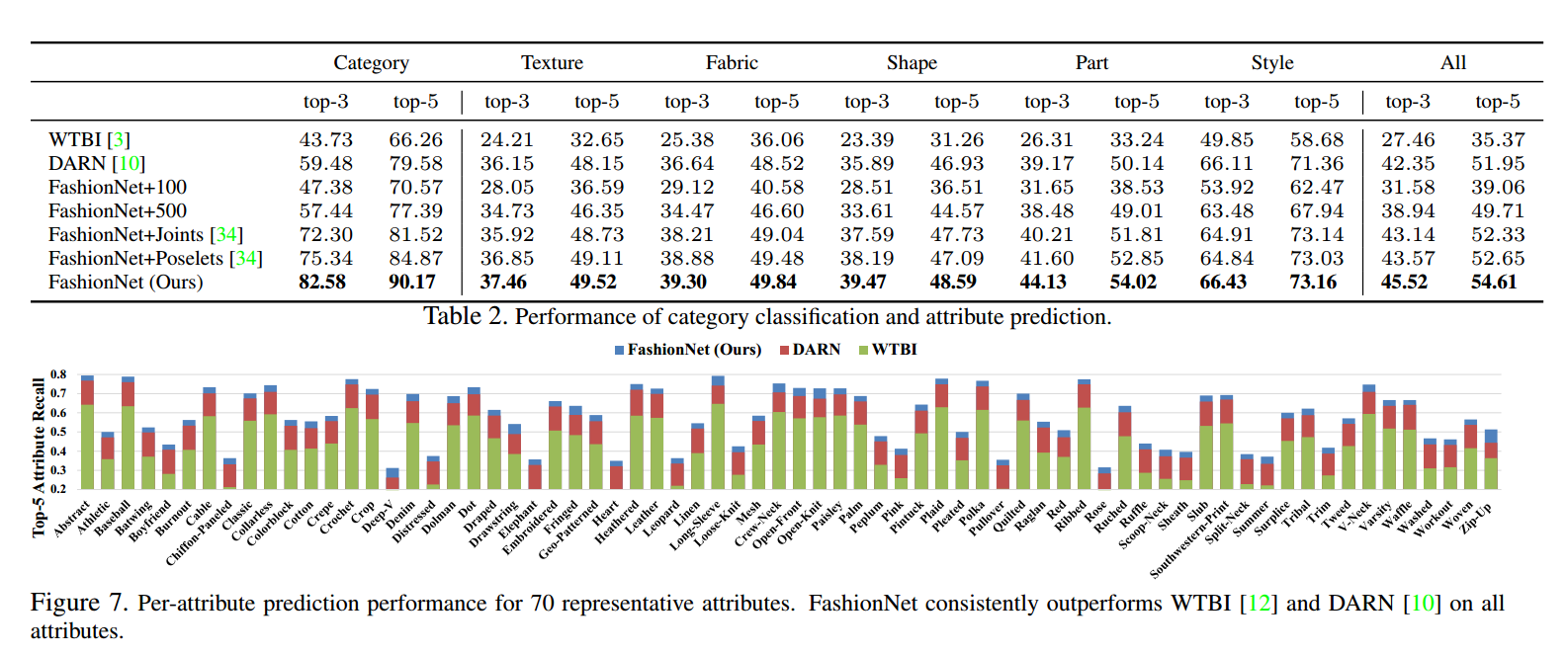
这个准确率,有很多可以压榨的空间。
4. 优化想法
- 将VGG-16换成更强特征extract能力的网络 ResNet 或者是Xception
- 引入technique,Hard-Aware/正负例学习
- 级联强监督?(不知道行不行
- 不检测landmark对于特性识别应该影响不大?可以剔除蓝色部分?